简介
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。(百度百科)
基础知识
- Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
- redis默认16个数据库,类似数组下表从零开始,默认数据库为0,可以使用SELECT id 命令切换指定数据库。
- Redis索引都是从零开始
- 统一密码管理,16个库都是同样密码,要么都OK要么一个也连接不上
- redis6.0前是单线程的,6.0后支持多线程,默认单线程
redis使用单线程原因
- 官方FAQ表示,因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。
- 不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
Redis的高并发和快速原因
- redis是基于内存的,内存的读写速度比硬盘快得多;(CPU高速缓存>内存>外存(硬盘、光盘、U盘等))
- redis是单线程的,省去了很多CPU上下文切换线程的时间;(CPU上下文切换是很耗内存的)
- redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll(Epoll是Linux内核为处理大批量文件描述符而作了改进的epoll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。)和自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间。“多路”指的是多个socket连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
常用命令
- keys * :查看所有key(*匹配所有字符,?匹配单个字符,如 keys ?ist可匹配 list,aist,bist……)
- info 查看redis详细信息,key数量也在里面
- set key value:存入键值对
- get key:获取key对应值
- DBSIZE:查看当前基本数据库大小(当前数据库的key的数量)。
- Flushdb:清空当前库 | Flushall:通杀全部库
- exists key : 判断key是否存在(存在返回1,不存在返回2)
- del key:删除key
- rename key newname:重命名key
- move key db_id :将当前数据库的 key 移动到给定的数据库 db 当中。
- type key :查看当前key存储类型
- expire key second(秒) 设置超时时间(即几秒后过期)
- ttl key 查看key剩余时间(-1表示永久有效,-2表示当前key不存在)
- persist key 移除过期时间,让key永久有效
- set key value [EX seconds] [PX milliseconds] [NX|XX] (EX 200:200秒后过期,NX:key不存在才操作,XX: key已存在才操作)
- shutdown:关闭redis
设置修改密码
1.客户端连接修改
1 | ##到安装目录下打开命令行 |
2.修改配置文件
1 | #找到redis.conf配置文件中的requirepass |
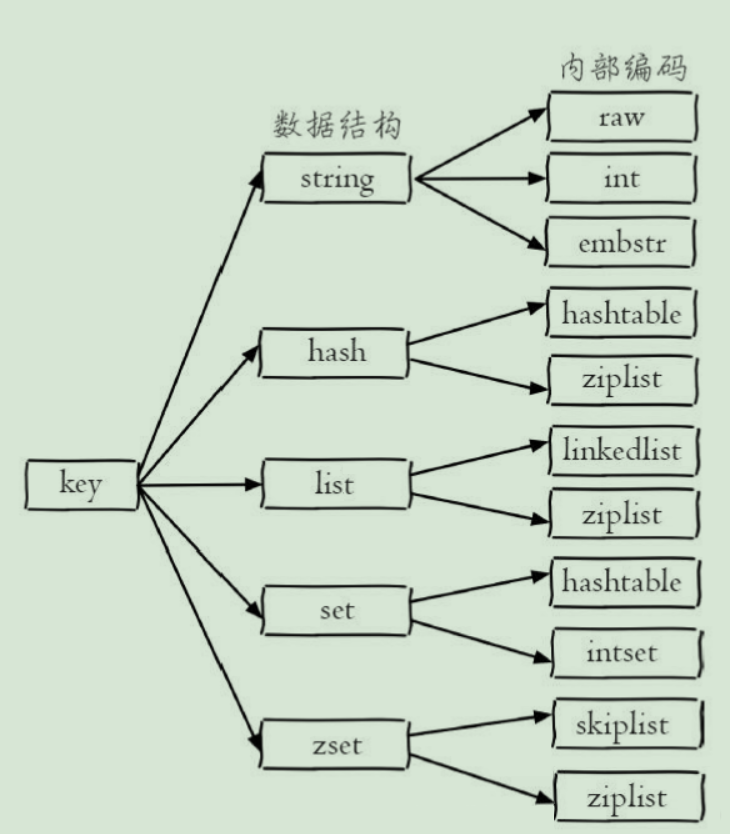
五大基本类型
字符串(String)
String是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
底层没有直接使用C字符串(即以空字符’\0’结尾的字符数组)作为默认的字符串表示,而是使用了SDS(简单动态字符串/Simple Dynamic String)
string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
补:String内部编码有三种方式,可使用object encoding key 查看。
- int : 长度小于20且保存的是64位有符号整型类型。
- embstr:长度小于等于44,对于嵌入式的String,从内存结构上说,就是字符串sds结构体与其对应的redisObject对象分配在同一块连续的内存空间,只需一次内存分配。
- raw:长度大于44,redisObject内存不在连续,采用指针的形式,实现连接。需要分配两次内存空间(分别为redisObject和sds分配空间)。
注:Redis中每个对象都是由redisObject表示的

常用操作:
append key value :往字符串后面追加字符串(若key不存在,则新建key,相当于set key value)
strlen key :返回字符串长度
incr key: 自增1
decr key:自减1
incrby key num:自增num
decrby key num:自减num
getrange key start end :截取字符串[start,end] [0,-1]表示全部
setrange key start str :用str替换指定位置开始的字符串
setex key seconds value:保存key-value并设置过期时间(set with expire)
setnx key value:不存在则设置(set if not exist),成功返回1,若已存在,则创建失败,返回-1
mset k1 v1 k2 v2 k3 v3:同时设置多个值
mget k1 k2 k3: 同时获取多个值
getset key value:先get后set,如果不存在则返回null,如果存在,则返回旧值,再设置新值
SDS组成结构
1 | struct __attribute__ ((__packed__)) sdshdr5 { |
- len:SDS字符串已使用的空间。
- alloc:申请的空间,减去len就是未使用的空间,初始时和len一致。
- flag:只使用了低三位表示类型,细化了SDS的分类,根据字符串的长度的不同选择不同的sds结构体,而结构体的主要区别是len和alloc的类型,这样做可以节省一部分空间大小。
- buf: 用了C的特性表示不定长字符串。
列表(List)
列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。它的底层是压缩列表(ziplist)或双端链表(linkedlist)(Redis3.2后改为快表quicklist,前两个的结合,实际上是个双端链表,链节点上存着压缩列表的引用指针)。
常用操作
LPUSH list value1 value2 value3 …… :将一个或多个值插入列表头部(左部)
LRANGE list start end :[start,end]通过区间获取列表具体值,[0,-1]获取list全部
RPUSH list value1 value2 value3 …… :将一个或多个值插入列表尾部(右部)
LPOP list :移除列表的第一个元素
RPOP list:移除列表的最后一个值
Lindex list index :通过下标获取 元素
Llen list:返回列表长度
Lrem lsit count value:移除list中count个value
ltrim list start end:通过下标截取list,原list已经被改变
rpoplpush sourceList newList:移除sourceList列表的最后一个元素,将他移动到newList列表中
lset list index newvalue: 替换将列表指定下标值(list或index不存在则报错)
linsert list value before|after newValue:将某一个具体的newValue插入到第一个value前面|后面
集合(Set)
Set是string类型的无序集合,不可重复。它是通过整数集合(intset)【当集合中的元素都是整数,且元素个数小于set-max-intset-entries配置值(默认512个)】或哈希表(hashtable)实现的。
常用操作
- sadd set value1 value2 value3 ……:往set集合添加元素
- smembers set:查看set元素
- sismembers set value:是否存在指定元素(存在返回1,不存在返回0)
- scard set:查看set集合元素数
- srem set value :移除set集合指定元素
- srandmember set (count):随机抽取num个元素(count不写默认一个)
- spop set (count):随机移除count个元素
- smove set1 set2 value:将set1中value移动到set2中
- sdiff set1 set2:set1与set2取差集,返回set1中存在,set2不存在的元素集合
- sinter set1 set2 :取交集
- sunion set1 set2:取并集
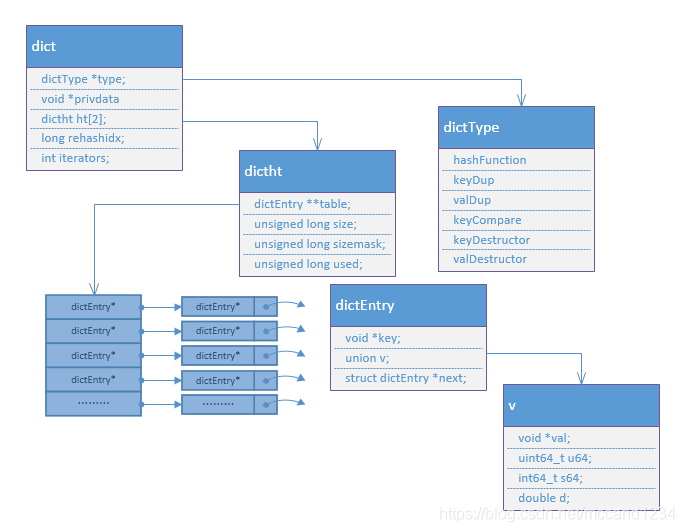
哈希(Hash)
hash 是一个键值对集合,是一个string类型的field和value的映射表,hash特别适合用于存储对象。类似Java里面的Map<String,Object>。底层是压缩列表(ziplist)或哈希表(hashtable)实现。
常用操作
- hset hash key value :存入hash一个 key-value键值对
- hget hash key:获取hash中key的值
- hmset hash key1 value1 key2 value2 ……:存入hash多个键值对
- hmget hash key1 key2 ……:获取hash多个key字段的值
- hgetall hash :获取全部key-value内容
- hdel hash key :删除hash中指定key字段
- hlen hash :返回hash长度
- hexists hash key:判断hash中key字段是否存在
- hkeys hash:返回所有key字段
- hvals hash:放回所有value
- hincrby hash key num:指定key增量num
- hsetnx hash key value:不存在则存入
有序集合(Zset)
zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。底层使用压缩列表(ziplist)或跳跃表(skiplist)实现。
redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
常用操作
ZADD key score1 member1 [score2 member2]:向有序集合添加一个或多个成员,或者更新已存在成员的分数.
ZCARD key 获取有序集合的成员数.
ZCOUNT key min max 计算在有序集合中指定区间分数[min,max]的成员数。
ZINCRBY key increment member:有序集合中对指定成员的分数加上增量 increment。
ZINTERSTORE newkey num key …:计算给定的一个或多(num)个有序集key的交集并将结果集存储在新的有序集合 newkey 中。
ZLEXCOUNT key min max:在有序集合中计算指定字典区间内成员数量。
min max: { - [a =(-∞,a]; - (a=(-∞,a);[a [b=[a,b];- +=(-∞,+∞)
ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合指定区间内的成员。-inf +inf = -∞ +∞
ZRANGEBYLEX key min max [LIMIT offset count] 通过字典区间返回有序集合的成员。
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] 通过分数返回有序集合指定区间内的成员。
ZRANK key member 返回有序集合中指定成员的索引。
ZREM key member [member …] 移除有序集合中的一个或多个成员。
ZREMRANGEBYLEX key min max :移除有序集合中给定的字典区间的所有成员。
ZREMRANGEBYRANK key start stop:移除有序集合中给定的排名区间的所有成员。
ZREMRANGEBYSCORE key min max移除有序集合中给定的分数区间的所有成员。
ZREVRANGE key start stop [WITHSCORES]返回有序集中指定区间内的成员,通过索引,分数从高到低。
ZREVRANGEBYSCORE key max min [WITHSCORES]返回有序集中指定分数区间内的成员,分数从高到低排序。
ZREVRANK key member返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序。
ZSCORE key member返回有序集中,成员的分数值。
ZUNIONSTORE destination numkeys key [key …]计算给定的一个或多个有序集的并集,并存储在新的 key 中。
ZSCAN key cursor [MATCH pattern] [COUNT count] 迭代有序集合中的元素(包括元素成员和元素分值)。
注
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1),其实不太准确。
其实在redis sorted sets里面当items内容大于64的时候同时使用了hash和skiplist两种设计实现。这也会为了排序和查找性能做的优化。所以如上可知:
- 添加和删除都需要修改skiplist,所以复杂度为O(log(n))。
- 但是如果仅仅是查找元素的话可以直接使用hash,其复杂度为O(1)
- 其他的range操作复杂度一般为O(log(n))
- 当然如果是小于64的时候,因为是采用了ziplist的设计,其时间复杂度为O(n)
五大基本类型底层实现
hashtable结构图
特殊类型
地理空间(geospatial )
Redis的Geo,3.2版本推出,可以推算地理位置的信息,两地之间的距离
城市经纬度查询:http://www.jsons.cn/lngcode/
六大操作
geoadd key 经度 维度 坐标名:添加地理位置(两级无法直接添加,可一次添加多个), 先经度后维度(官方文档疑似写错了)
例:geoadd china:city 116.405285 39.904989 beijing 121.4 31.2 shanghai ……
key 经度 维度 地理名称
geopos key name1 name2……:获取key中name的地理位置
例:GEOPOS china:city beijing shanghai shenzhen xianggang
georadius key 经度 维度 距离: 以给定的经纬度为中心,找出某一半径内所有的元素
例:GEORADIUS china:city 110 30 1000 km [withcoord] [withdist]
GEORADIUSBYMEMBER key 坐标名(元素名) 距离 :根据给定的元素确定中心点,再进行查找
例:GEORADIUSBYMEMBER china:city beijing 1000 km [withcoord] [withdist]
GEODIST key name1 name2 [单位] :返回指定单位中两个指定成员之间的距离。如果缺少一个或两个成员,该命令将返回NULL。
例:GEODIST china:city beijing xianggang km
GEOHASH key name1 name2……:该命令返回11个字符的Geohash字符串,因此与Redis内部52位表示形式相比,不会损失任何精度。该命令返回一个数组,其中每个元素是与作为参数传递给命令的每个成员名称相对应的Geohash。
返回的Geohashhes具有以下属性:
- 以从右侧删除字符来缩短它们。它将失去精度,但仍将指向同一区域。
- 可以在
geohash.orgURL中使用它们,例如http://geohash.org/<geohash-string>。这是此类URL的示例。 - 前缀相似的字符串在附近,但事实并非如此,前缀不同的字符串也可能在附近。
geo底层实现原理其实是zset,我们可以使用zset命令操作他
zrange key 0 -1:查看地图key中的所有元素
zrem key member:删除key中指定元素
Hyperloglog
简介:Hyperloglog 可用于基数统计(基数:在数学上,是集合论中刻画任意集合集大小的一个概念。即一个集合中不重复的元素数。)
redis2.8.9后更新了hyperloglog数据结构
示例:网页UV
uv(Unique Visitor):网站的独立访客,统计1天内访问某站点的用户数(以cookie为依据);访问网站的一台电脑客户端为一个访客。可以理解成访问某网站的电脑的数量。
访问用户量大的情况下,若用传统的set集合统计将耗费大量内存。使用hyperloglog基数统计占用内存固定,2^64不同的元素,只需要废12kb内存。(官网统计hyperloglog有0.81%的错误率,但在统计UV任务上,我们可以忽略不计)
操作
PFADD keyset value1 value2 value3……往集合keyset中添加元素
PFCOUNT keyset:统计集合keyset的基数
PFMERGE newset keyset1 ketset2:将集合keyset1和keyset2的元素合并(并集)到newset中
Bitmap(位存储)
简介: Biymaps位图,该数据结构都是操作二进制位来记录数据的,就只有0和1两个状态。(适用于只有两个状态的数据)
操作
setbit sign index value:往sign的index(从0开始)位置上存value(0或1)
getbit sign index :获取sign中index位上的值(默认0)
bitcount sign:统计sgin中为1的数量
注:bitcount sign start end 获取sgin中第start字节到end字节的1的数量
1 | 127.0.0.1:6379> set k bb |


