JVM架构模型
简介
Java编译器输入的指令流基本上是一种基于栈的指令集架构,与之对比的是另外一种基于寄存器的指令集架构。
区别
基于栈式架构特点:
- 设计简单,资源受限等小型系统也适用。
- 避开寄存器的分配难题,直接使用零地址指令,指令集更小,实现更加简单。
- 不需要硬件支持,可移植性更好,更好实现跨平台。
基于寄存器架构特点
- 指令集架构完全依赖硬件,可移植性差。
- 指令执行更高效,性能更好。
- 花费更少指令完成一项操作。
总结
由于跨平台的设计,java的指令都是根据栈来设计的,不同平台的CPU架构不同,所以不能设计基于寄存器的。基于栈来设计的优点是跨平台,指令集小,编译器更容易实现。缺点是性能下降,实现同一项操作需要更多指令。
JVM生命周期
启动
通过引导类加载器(bootstrap class loader)创建一个初始类来完成,一个Jvm启动后就是一个进程。
注:可在命令窗口使用jps指令查看当前进程id
运行
执行Java程序,即执行一个叫做java虚拟机的进程。
退出
- 程序执行结束正常退出。
- 程序执行过程中遇到异常或错误而异常终止。
- 操作系统出现错误导致JVM进程终止。
- 程序中执行System.exit(status)或Runtime.getRuntime().halt(status)方法。
- 除此之外,JNI(Java Native Interface)规范描述了JNI Invocation API来加载或卸载java虚拟机时,java虚拟机退出的情况。
字节码执行过程
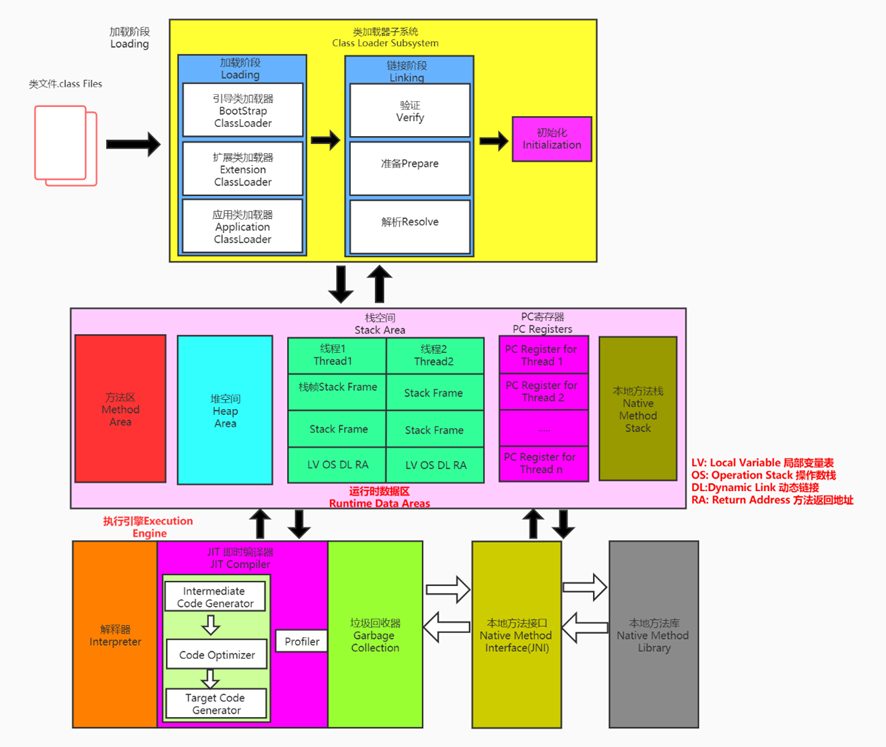
类加载子系统
负责将字节码文件即class文件加载到JVM中,加载的类信息将存储于JVM运行时数据区的方法区中。(除类信息外,方法区还存放运行时的常量池信息等)
类加载过程
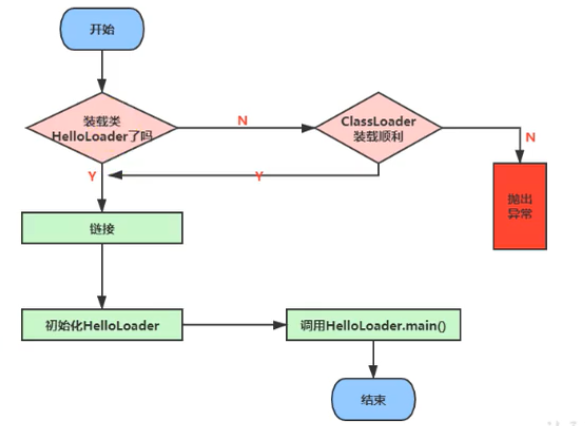
加载
- 通过类的全限定类名获取此类的二进制字节流。
- 将字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在内存中生成代表这个类的Class对象,作为方法区这个类的各种数据的访问入口。
链接
1.验证(Verify)
目的:保证Class文件的字节流中包含的信息符合当前虚拟机的要求,保证被加载类的正确性以及虚拟机自身安全。
- 文件格式验证
- 元数据验证
- 字节码验证
- 符号引用验证
2.准备(Prepare)
为类变量(静态属性)分配内存并设置默认初始值,即零值。
注:
- final修饰的static除外,因为final在编译的时候就分配了,准备阶段会显式初始化。
- 实例变量(普通属性)不会被分配初始化,类变量会被分配在方法区中,而实例变量会随java对象一起分配在堆中。
3.解析(Pesolve)
将常量池的符号引用转换为直接引用(直接引用就是直接指向目标的指针,相对偏移量或间接定位到目标的句柄)。主要针对的是类的接口、字段、类方法、接口方法、方法类型等。
初始化
- 本质:就是执行类构造方法clinit()的过程。
- 此方法不需要定义,javac编译器自动收集类中所有类变量的赋值动作和静态代码块中的语句。
- 指令的执行顺序会按代码在源文件出现的顺序执行。
- 若该类有父类,JVM会先加载并执行完父类的clinit()方法。clinit()方法在多线程下是被同步加锁的。
类加载器
注:所有派生于抽象类ClassLoader的类加载器都划分为自定义类加载器(User-Defined ClassLoader)(即只有Bootstrap 不是)。
引导(启动)类加载器(Bootstrap ClassLoader)
- 由C/C++语言实现,嵌套在JVM内部。
- 用来加载Java核心库(JAVA_HOME/jre/lib/rt.jar、resourse.jar或sun.boot.class.path路径下的内容),提供JVM自身所需类。
- 并不继承自java.lang.ClassLoader,没有父加载器,加载扩展类加载器并指定为他们的父类加载器。
- 出于安全考虑,Bootstrap启动加载器只加载包名为java、javax、sun等开头的类。
扩展类加载器(ExClassLoader)
- Java语言编写,由sun.mis.Launcher$ExtClassLoader实现。
- 派生于ClassLoader类,父类加载器为Bootsrap ClassLoader 。
- 从java.ext.dirs系统属性所加载类库,或从JDK的安装目录的jre/lib/ext子目录(扩展目录)下加载类库。如果用户创建的JAR包放在此目录下,也会自动由扩展类加载器加载。
系统类(应用程序类)加载器(AppClassLoader)
- Java语言编写,由sun.mis.Launcher$AppClassLoader实现。
- 派生于ClassLoader类,父类加载器为Bootsrap ClassLoader 。
- 负责加载类环境变量classpath或系统属性 java.class.path 指定路径下的类库
- 程序中的默认加载器,一般来说,Java应用类都是由它来完成加载
- 可以通过ClassLoader.getSystemClassLoader()方法获取
用户自定义类加载器
- 作用:隔离加载类、修改加载方式、扩展加载源、防止源码泄露。
- 实现:可继承java.lang.ClassLoader或java.net.URLClassLoader类实现自己的类加载器,
双亲委派
一个加载器收到类加载请求,不会自己先去加载,而是先将请求委托给父类的加载器去执行,若父类加载器还有其父类加载器,则进一步向上委托,依次递归到启动类加载器,父类加载器可以加载则成功返回,无法加载则子类再去加载。
优势:
避免类重复加载,保护程序安全,防止核心API被随意算改
沙箱安全机制
如我们在程序中自己定义了一个 String 类,但是加载自定义 String 类的时候会先使用引导类加载器加载,而引导类加载器在加载的过程中会先加载 JDK 自带的文件(rt.jar 包中的 java\lang\String.class),这样可以保证对 java 核心源代码的保护,这就是沙箱安全机制。
运行时数据区
程序计数器(Program Counter Register)
简介
又称PC计数器、指令计数器,程序钩子。JVM的PC寄存器是对物理PC寄存器的抽象模拟。占用内存少,几乎可忽略不记,运行速度最快的存储区域。在JVM规范中,每个线程独享一个程序计数器,生命周期与线程一致。任何时期每个线程都只有一个方法在执行,也就是当前方法。程序计数器会存储当前线程正在执行的Java方法的JVM指令地址;如果是正在执行本地方法,则是未指定值(undefned)。
作用
- 用来存储指向下一条指令的地址,也即将要执行的指令代码。由执行引擎读取下一条指令。
- 程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
- 字节码解释器工作时需要通过计数器的值来选取下一条需要执行的字节码指令。
- 它是唯一一个在Java虚拟机中没有规定任何OutOfMemoryError情况的区域。
虚拟机栈(JVM Stacks)
简介
Java虚拟机栈(Java Virtual Machine Stack),早期也叫Java栈,每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个栈帧(Stack Frame),对应着一次次的Java方法调用。生命周期与线程一致。
优点
- 栈是一种快速有效的分配存储方式,访问速度仅次于程序计数器。
- JVM对Java的栈操作只有两个:进栈(入栈、压栈)【方法执行】,出栈【方法结束】。
- 栈不存在垃圾回收问题。
可能存在异常
- 栈大小固定:StackOverflowError
- 栈大小可动态扩展:OutOfMemoryError
栈帧
又称局部变量数组或本地变量表,定义为一个数字数组,主要存储方法参数和定义在方法体内的局部变量【基本数据类型、对象引用、以及returnAddress类型】,局部变量表是建立在线程栈上的,线程私有,不存在数据安全问题,表容量大小是编译期确定下来,最基本单位是slot(变量槽)32位以内类型占一个slot,64位类型占两个。
注:若当前帧是由构造方法或实例方法创建的,那么该栈帧的slot的index=0存放的是该对象的引用—this
在方法执行过程中,根据字节码指令,往栈中写入数据或提取数据,即入栈(push)/出栈(pop)。主要用于保存计算过程的中间结果。其栈深度在编译期就定义好,保存在方法的Code属性中,为max_stack的值。32位占一个、64位占两个单位的栈深度。
栈顶缓存(Top-of-Stack Cashing)技术:将栈顶元素全部缓存在物理cpu的寄存器中,以此降低对内存的读写次数,提升执行引擎的执行效率。
每个栈帧都包含一个指向常量池中该栈帧所属方法的引用。动态链接就是将变量和方法的引用转换为调用方法的直接引用
正常退出:调用者的pc计数器的值作为返回地址,即调用该方法的下一条指令地址。
异常退出:异常表来确定。
区别:异常退出的不会给他的上层调用者产生任何返回值。
对程序调试提供支持的信息
本地方法栈(Native Method Stacks)
Java虚拟机栈用于管理Java方法的调用,而本地方法栈用于管理本地方法的调用
堆(Heap)
一个JVM实例只存在一个堆内存,堆也是Java内存管理的核心区域(最大的内存空间),堆可以在物理上不连续,但在逻辑上它应该被视为连续的,堆区域是所有线程共享的,但也有划分出线程私有的缓存区Thread Local Allocation Buffer(TLAB,解决指针冲突)。
可细分为新生区和养老区;
新生区又可细分为Eden,Survivor0,Survivor1三个空间 (也称Eden, from, to), 官网说默认比例是8:1:1 。
实际操作发现并不是,需关闭自适应内存分配策略:-XX:-UseAdaptiveSizePolicy,或直接通过-XX:SurvivorRatio=8调整此比例
设置堆空间新生代和老年代占比
1 | -XX:NewRatio= #设置新生代和老年代空间占比,默认2 |
idea可直接在Run->Eidt Configurations->VM options里设置(注:设置多个时用空格隔开)
1 | #-X 是jvm的运行参数 m是memory, s是start, x是max |
命令行查看运行参数
1 | jstat -gc 【进程id】 【打印间隔时间单位(秒或毫秒),不指定默认毫秒】(不写只打印一次)#查看进程GC情况 |
垃圾回收GC
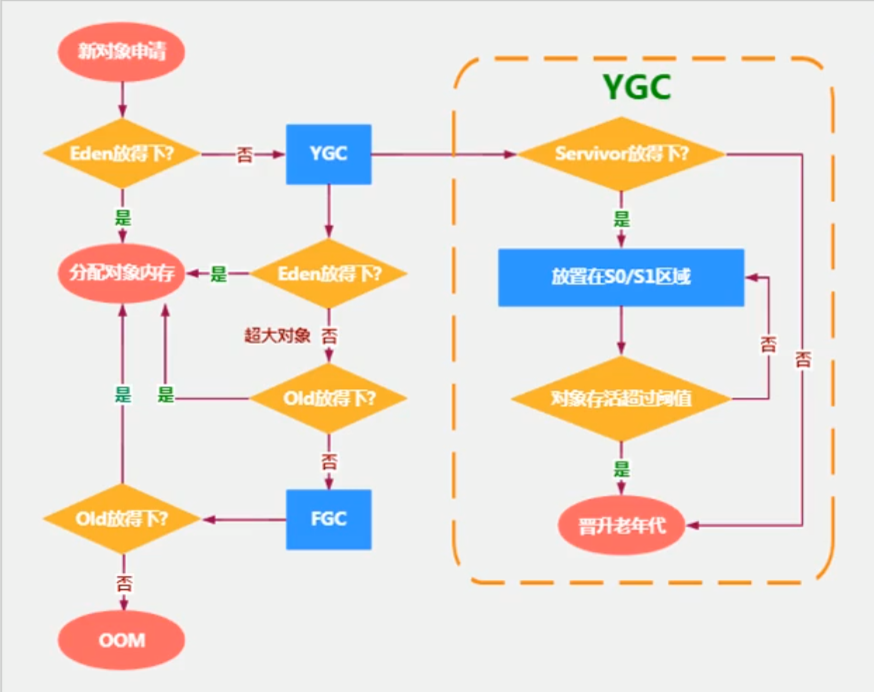
STW(Stop The World):
指在进行垃圾回收时,暂停其它用户线程,等垃圾回收结束,用户线程才能恢复运行。
新生代收集MinorGC(Young GC)
清理年轻代的内存,Survivor中基数达到15的对象移至老年代,当年轻代Eden空间满时触发,Survuivor满不会触发GC
老年代收集MajorGC(Old GC)
目前只有CMS GC会有单独收集老年代的行为,很多时候Major GC会和Full GC混合使用。Major GC的速度一般会比Minor GC慢10倍以上。STW更长
Major GC经常会胖随至少一次Minor GC,若Major GC后内存还不足,就直接报OOM。
混合收集(Mixed GC)
目前只有G1 GC会有这种行为。
整堆收集FullGC
收集整个java堆和方法区的垃圾。
触发条件:
- 调用System.gc(),系统建议执行,但不是必须执行。
- 老年代空间不足。
- 方法区空间不足。
- 通过Minor GC后进入老年代的平均大小大于老年代的可用内存。
方法区(Metaspace)
简介
方法区是线程共享的,jdk7以前永久代实现,jdk8后改为元空间(Metaspace )使用本地内存。存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等。
方法逃逸
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术。这是一种可以有效减少Java 程序中同步负载和内存堆分配压力的跨函数全局数据流分析算法。通过逃逸分析,Java Hotspot编译器能够分析出一个新的对象的引用的使用范围从而决定是否要将这个对象分配到堆上。
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
jdk1.7后默认开启
1 | -XX:+DoEscapeAnalysis #开启方法逃逸 |
常见问题
一、为什么要字节码,用不同平台虚拟机直接将java代码编译成对应指令集不就行?
- 准备工作:(源代码———> 机器码)每次执行都需要检查语法和语义检查,每次执行语义分析的结果都不会被保留下来,都要重新编译,重新去分析,整体性能会受到影响,做很多重复的事情,因此引出中间字节码,保证一次编译,多次运行时不需要重复校验。
- 兼容性:也可以将别的语言解析成字节码,例如scala,生成字节码同样也可以被JVM调用执行,提高平台兼容扩展能力,符合软件设计的中庸之道。
二、堆是内存分配对象的唯一选择码?
随着JIT编译期的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。
在Java虚拟机中,对象是在Java堆中分配内存的,这是一个普遍的常识。但是,有一种特殊情况,那就是如果经过逃逸分析(Escape Analysis)后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配。这样就无需在堆上分配内存,也无须进行垃圾回收了。这也是最常见的堆外存储技术。
此外,基于openJDK深度定制的TaoBaoVM,其中创新的GCIH (Gcinvisible heap)技术实现off-heap,将生命周期较长的Java对象从heap中移至heap外,并且Gc不能管理GCIH内部的Java对象,以此达到降低Gc的回收频率和提升GC的回收效率的目的。
注:《深入理解Java虚拟机》
三、 什么是解释器(Interpreter),什么是即时编译器(JIT)
解释器:当java虚拟机启动时,会根据预定义的规范对字节码文件进行逐行解释的方式执行。每条指令都会被翻译成机械指令执行。
JIT(Just In Time)编译器:虚拟机直接将源码转换成可以直接发送给处理器的指令的程序。
四、 为什么说java是半编译半解释型语言
- jdk1.0时代,java虚拟机的执行引擎只用解释器将字节码逐行翻译成机械指令执行,效率较慢,此时可算解释型语言。
- 现在虚拟机的执行引擎里有JIT编译器,可直接将方法编译成机械码后再执行,通常两者会结合使用,所以说java是半编译半解释型语言。
五、JIT比解释器快,为啥不直接只使用JIT
虚拟机刚启动时,解释器可以先发挥作用(表现为启动时响应用户更快),即时编译器全部编译完再执行,需要一定时间等待。随着时间的推移,即时编译器逐渐发挥作用,利用热点探测功能, 将有价值的字节码编译成本地机械指令,以换取更高的执行效率。




