数据库索引失效情况
查询不同条件中使用or(若只查询相同字段不同情况用or还是会走索引)
注:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
查询使用is not null判断
- 单列索引无法存储null,复合索引无法储存全为null的值。
- 索引是有序的,插入数据时需要对其进行比较,null无法比较,无法确定其位置。
(解决,可自定义特定值替代null值,或使用复合索引)
注:在二级索引树的结构上,值为NULL的记录会被放在索引的最左边。
模糊查询使用%开头 如 like ‘%this’
注:若不是%开头的模糊查询,如’XX%’,可用XX去匹配索引列,当碰到其他开头的数据时,就可以停止查找了,因为后面的数据一定不满足要求。这样就可以利用索引了。以%开头的就难以定位,执行引擎可能更倾向于全表扫描。
若索引列是字符串型时,查询条件要用’’引起来,否则不使用索引
存在类型转换
如:整型字段条件却用字符(where num = ‘123’)
如果mysql估计使用全表扫描要比使用索引快,则不使用索引
如:表中列与列间的对比,在同一表中的两个列都建了索引,条件是where column1 = column2时,会被认为不如走全表扫描
索引列的数据都一样时
注:索引不应被建在数据几乎一样的列上
MySQL索引类型
B-Tree索引
B树索引底层使用多路平衡查找树,具有范围查找和前缀查找的能力,对于有N节点的B树,检索一条记录的复杂度为O(LogN)。相当于二分查找。InnoDB存储引擎的默认索引实现为:B+树索引。
Hash索引
MyISAM支持索引,哈希索引底层是Hash表只能做等于查找,但是无论多大的Hash表,查找复杂度都是O(1)。InnoDB 引擎中叫作自适应哈希索引,在自适应hash特性里有使用。
空间数据索引(R-tree)
myisam支持空间索引,可以用作地理数据存储,R-tree无须前缀索引。空间索引会从所有维度来索引数据。查询时,可以有效地使用任意维度来组合查询。(MyISAM和InnoDB引擎【mysql5.7.4】支持)
全文索引
通过查找文本中的关键词,类似于搜索引擎,而不是简单的where条件匹配。(MyISAM和InnoDB引擎【mysql5.6】支持)
小结
如果值的差异性大,并且以等值查找(=、 <、>、in)为主,Hash索引是更高效的选择,它有O(1)的查找复杂度。如果值的差异性相对较差,并且以范围查找为主,B树是更好的选择,它支持范围查找。
MySQL8.0无法对表一个字段同时添加外键和check
1 | CREATE TABLE 开课表 |
解决
使用触发器替代check
注:在MYSQL8.0前,CHECK只是一段可调用但无意义的子句,MySQL会直接忽略。
1 | delimiter $ --更改结束符 |
Mysql用触发器实现修改同一字段
1 | --需求修改工号同时修改负责人 |
在存储过程中使用游标操作多个数据
1 | DELIMITER $$ --将sql分割符声明为$$ |
查询数据库表数量
所有表数量
1 | SELECT COUNT(*) table_num, table_schema FROM information_schema.TABLES |
各数据库表数量
1 | SELECT COUNT(*) table_num, table_schema FROM information_schema.TABLES GROUP BY table_schema; |
查询指定库的表数量
1 | SELECT COUNT(*) table_num, table_schema FROM information_schema.TABLES where table_schema = '库名' |
inndb关键特性
二次写(double write)
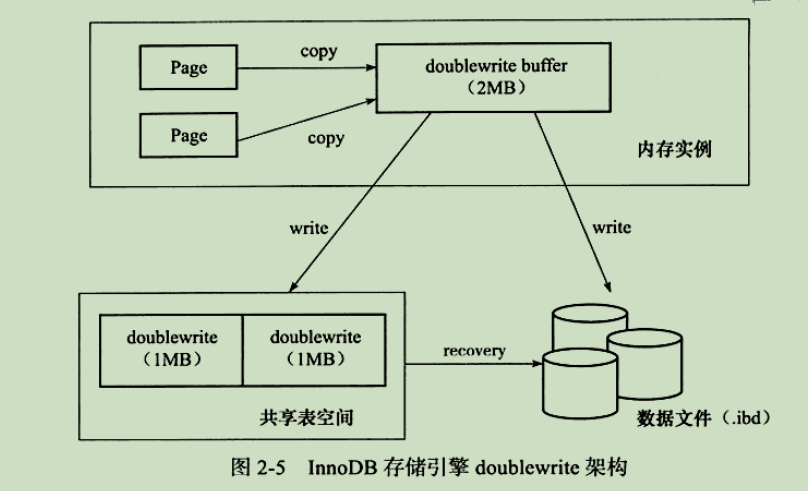
异步IO(Async IO)
可以同时发送多个IO请求,然后等待所有IO操作完成。
IO Merge:将多个合成为一个IO,例如访问的页(space, page_no)为(8,6)(8,7)(8,8),则合成为一个IO请求从(8,6)开始。连续读48K页面。
邻接表刷新
- 磁盘预读原理。当刷新一个脏页时,InnoDB会检测该页所在区的所有页,如果是脏页则一起刷新。
插入缓存
- 主要是插入性能提升。解决频繁数据更新带来的b+tree频繁自平衡工作。
- 对于非聚集索引的插入/更新操作先判断非聚集索引的页是否在缓冲池中,若在则直接插入。
- 若不在则先放入到一个InsertBuffer中,然后按一定频率对InsertBuffer和辅助索引页进行merge操作。
- 这是一种插入合并,减少b+tree重排。
- 索引不能是主键索引,主键索引为聚集索引,大多为自增。如果为UUID类型,则可以使用InsertBuffer
- 索引非唯一,因为数据库并不会去查找索引页来判断插入的唯一性。
- 1.2以后进行了升级,Change Buffer,将DML操作细分为InsertBuffer, DeleteBuffer, PurgeBuffer
- update时,DeleteBuffer是第一个过程,标记为删除。PurgeBuffer为第二个过程,真正移除。
- InsertBuffer的内部实现是一颗B+tree,负责对所有表的的辅助索引进行InsertBuffer。
- 它存放在共享表空间中,也就是ibdata1中,所以通过ibd进行文件恢复时,需要进行RepairTable重建表上辅助索引。
自适应hash
Hash查找的时间复杂度为O(1), 而B+tree的查找次数一般约等于3~4层。innodb会根据访问频率和模式来自动为某些热点页建立hash。
要求访问模式也就是查询条件固定且为=搜索,而不是范围检索。
当以该模式访问了100次,且页通过该模式访问了N次,其中N=页中记录数*1/16。
注:详细在《MySQL技术内幕 InnoDB存储引擎 第2版》58页。
MVCC多版本并发控制
MySQL的锁
- 表级(MyISAM、MEMORY和InnoDB)
- 页级(BDB)
- 行级(InnoDB)
MySQL多表连接细节
mysql表与表之间的关联查询使用Nested-Loop join算法,顾名思义就是嵌套循环连接,但是根据场景不同可能有不同的变种:比如Index Nested-Loop join,Simple Nested-Loop join,Block Nested-Loop join, Betched Key Access join等。
在使用索引关联的情况下,有Index Nested-Loop join和Batched Key Access join两种算法。
在未使用索引关联的情况下,有Simple Nested-Loop join和Block Nested-Loop join两种算法。
索引类型type
type索引类型:system > const > eq_ref > ref > range > index > all。优化级别从左往右递减,没有索引的一般为all。
字符集
- ASCII字符集使用1个字节编码,共收录128个字符,包括空格、标点符号、数字、大小写字母和一些不可见字符。
- ISO 8859-1字符集使用1个字节编码,共收录256个字符,是在ASCII字符集的基础上又扩充了128个西欧常用字符(包括德法两国的字母)。这个字符集也有一个别名latin1。
- GB2312字符集,变长编码方式,收录了汉字以及拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母。其中收录汉字6763个,其他文字符号682个。同时这种字符集又兼容ASCII字符集,所以在编码方式上显得有些奇怪:如果该字符在ASCII字符集中,采用1字节编码。否则采用2字节编码。
- GBK字符集GBK字符集只是在收录字符范围上对GB2312字符集作了扩充,编码方式上兼容GB2312。
- utf8字符集收录地球上能想到的所有字符,而且还在不断扩充。这种字符集兼容ASCII字符集,采用变长编码方式,编码一个字符需要使用1~4个字节。
准确的说,utf8只是Unicode字符集的一种编码方案,Unicode字符集可以采用utf8、utf16、utf32这几种编码方案,utf8使用1~4个字节编码一个字符,utf16使用2个或4个字节编码一个字符,utf32使用4个字节编码一个字符。
mysql中的utf-8:
utf8mb3:阉割过的utf8字符集,只使用1~3个字节表示字符。
utf8mb4:正宗的utf8字符集,使用1~4个字节表示字符。
查询mysql执行计划(Explain )
1 | mysql> explain select * from user; |
字段介绍
| 列名 | 描述 |
|---|---|
| id | 在一个大的查询语句中每个 SELECT 关键字都对应一个唯一的 id |
| select_type | SELECT关键字对应的那个查询的类型 |
| table | 表名 |
| partitions | 匹配的分区信息 |
| type | 针对单表的访问方法 |
| possible_keys | 可能用到的索引 |
| key | 实际上使用的索引 |
| key_len | 实际使用到的索引长度 |
| ref | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | 预估的需要读取的记录条数 |
| filtered | 某个表经过搜索条件过滤后剩余记录条数的百分比 |
| Extra | 一些额外的信息 |
Extra
No tables used:当查询语句的没有 FROM 子句时将会提示该额外信息,如 explain select 1
Impossible WHERE:查询语句的 WHERE 子句永远为 FALSE 时,如where 1 != 1
No matching min/max row:当查询列表处有 MIN 或者 MAX 聚集函数,但是并没有符合 WHERE 子句中的搜索条件的记录如 explain select MIN(id) from user where id=-1;
Using index:索引覆盖即不需要回表查询,如 explain select id from user where id>1;
Using index condition:索引条件下推时提示。
索引条件下推:使用索引条件提前过滤,减少查询次数,如
explain select * from user where account > '001' and account like '%12';like ‘%12’ 无法用到索引,但是可在回表前先过滤,减少回表查询次数。Using where:使用全表扫描来执行对某个表的查询,并且该语句的 WHERE 子句中有针对该表的搜索条件。
Using join buffer (Block Nested Loop):在连接查询执行过程中使用基于块的嵌套循环算法。
Not exists: 外连接时,WHERE 子句中包含要求被驱动表的某个列等于 NULL 值的搜索条件explain select * from user left join follower on user.id = follower.followed_id where follower.id is null;
Using intersect(…) 、 Using union(…) 和 Using sort_union(…):使用索引合并的方式执行查询。
Zero limit:使用LIMIT 0;
Using filesort:使用文件排序方式。
注: filesort很耗费性能,应该尽量将文件排序的执行方式改为使用索引进行排序
- Using temporary:使用到临时表,如去重,分组等操作。
注:MySQL 会在包含 GROUP BY子句的查询中默认添加上 ORDER BY 子句,
如 group by id == group by id order order id
所以有group by的sql的Extra 一般都有 Using temporary; Using filesort
Start temporary, End temporary:通过建立临时表来实现为外层查询中的记录进行去重操作时,驱动表查询执行计划的 Extra 列将显示 Start temporary 提示,被驱动表查询执行计划
的 Extra 列将显示 End temporary 提示
LooseScan,FirstMatch :In 子查询转为 semi-join 时,使用的执行策略。
其他学习链接
存储长度问题
MySQL中VARCHAR最大长度是多少?CHAR和VARCHAR有哪些区别?
MySQL的varchar水真的太深了——InnoDB记录存储结构
MySQL字段长度、取值范围、存储开销(5.6/5.7/8.x的主要类型,区分显示宽度/有无符号/定点浮点、不同时间类型)




