数据挖掘
数据挖掘一般是指从大量数据中通过算法搜索隐藏于其中的信息的过程(数据采矿)。
概述
数据挖掘的定义
技术层面
数据挖掘就是从大量数据中, 提取潜在的有用信息和知识的过程。
商业层面
数据挖掘就是一种商业信息处理技术。其主要特点是对大量业务数据进行抽取、转换、分析和建模处理,从中提取辅助商业决策的关键性数据。
数据挖掘与传统数据分析方法(如查询,报表,联机应用分析等)的区别
本质区别: 数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先前未知、有效和实用三个特征。其主要目标就是提高决策能力,能在过去的经验基础上预言未来趋势等。
数据挖掘任务
预测任务
根据其它属性的值预测特定属性的值,如分类、回归、离群点检测。
描述任务
寻找概括数据中潜在联系的模式,如聚类分析、关联分析、演化分析、序列模式挖掘。
数据挖掘-入侵检查
- 入侵可以定义为任何**威胁网络资源(**如用户账号、文件系统、系统内核等)的完整性、机密性和可用性的行为。
- 大多数商业入侵检测系统主要使用误用检测策略,这种策略对已知类型的攻击通过规则可以较好地检测,但对新的未知攻击或已知攻击的变种则难以检测。
- 异常检测通过构建正常网络行为模型(称为特征描述),来检测与特征描述严重偏离的新的模式。
数据预处理
主要任务
数据清理:填写空缺数据,平滑噪声数据,识别、删除孤立点,解决不一致性。
数据集成:集成多个数据库,数据立方体或文件中的数据,存放到一个一致的数据存储设备中(需考虑一致性和冗余问题)。
数据变换: 规范化和特征构造。

- 数据归约:得到数据集的压缩表示及特征选择(从记录和维度两方面减少数据量)。
- 离散化:通过将属性域划分为区间,减少给定连续属性值的个数。
相似性度量
- 曼哈顿(Manhattan)。
- 欧几(Euclidean)里得距离。
- 切比雪夫(Chebyshev)距离。
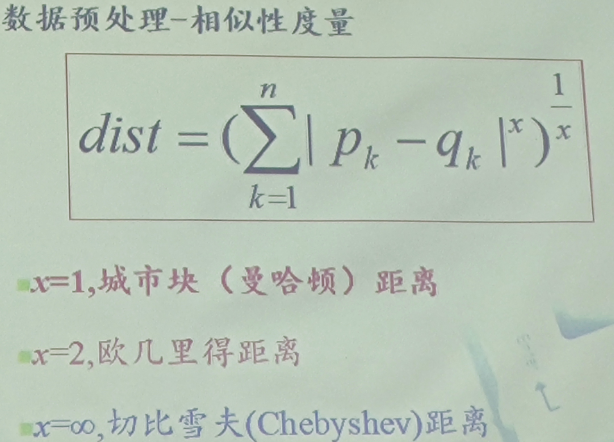
分类
分类的任务是对数据集进行学习并构造一个拥有预测功能的分类模型,用于预测未知样本的类标号。
- 首先将数据集划分为2部分: 训练集和测试集。
- 第一步:对训练集学习,构建分类模型。
- 第二步:用建好的分类模型对测试集分类。
- 最后,使用分类准确度高的分类模型对类标号未知的未来样本数据进行分类。
分类方法
- 基于决策树的分类方法
- 贝叶斯分类方法
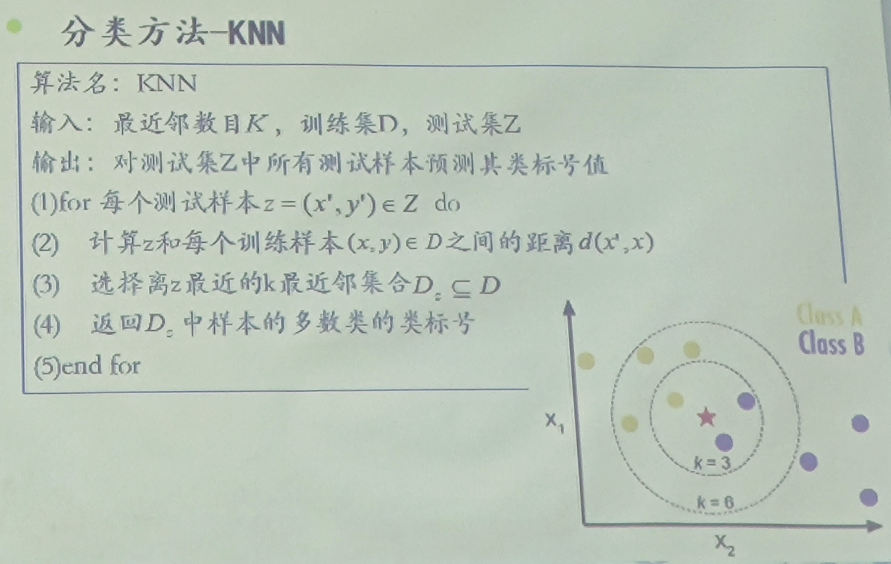
- K-最近邻分类方法
- 神经网络方法
- 支持向量机方法
- 集成学习方法
- ……
基于决策树的分类方法

注:信息增益越大,说明使用属性A划分后得样本子集越纯,越有利于分类。
贝叶斯分类方法(Bayes)

K-最近邻分类方法
其他度量指标

精度(Precision)
正确分类的正例个数占分类为正例的样本个数的比例。
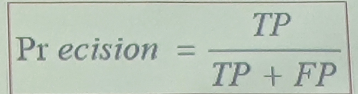
召回率(Recall)
正确分类的正例个数占实际正例个数的比例。

聚类
聚类(Clustering)是将数据集划分为若干相似对象组成的多个组(group)或簇(cluster)的过程,使得同一组中对象间的相似度最大化,不同组中对象间的相似度最小化。或者说一个簇(clustc)就是由彼此相似的一组对象所构成的集合,不同簇中的对象通常不相似或相似度很低。


关联分析
发现对象与特征之间相互依赖的关系,通常是从给定的数据集中发现频繁出现的模式知识(又称为关联规则)。关联分析广泛用于市场营销、事务分析等领域。
项集
在关联分析中,包含0个或多个项的集合,称为项集,一个包含k个数据项的项集称为k-项集。
频繁项集
一个项集的支持度大于或等于某个阈值,则称为频繁项集。
支持度计数
一个项集的出现次数就是整个交易数据集中包含该项集的事务数,也称为该项集的支持度计数。
支持度
一个项集的出现次数与数据集所有事务数的百分比称为该项集的支持度。
support(A -> B) = support_count(A ∪ B) / N; (N表示数据集的事务数)
置信度
置信度是一个数据集中包含A事务同时包含B事务的百分比,置信度确定B在包含A事务中出现的频繁程度,表示规则在数据集上的可靠性。
confidence(A->B) = support_count(A ∪ B) / support_count(A);
强关联规则
大于最小支持度阈值和最小置信度阈值的关联规则称为强关联规则。
提升度
提升度(lift)是一种简单的相关度量。对于项集A和项集B,如果P(A ∪B) = P(A)P(B),则A和B相互独立,否则存在某种依赖关系关联规则的前件项集A和后件项集B之间的依赖关系通过提升度计算。提升度可以评估项集A的出现是否能够促进项集B的出现。
lift(A,B) = confidence(A->B)/support(B);
lift(A,B) > 1 ,表示A,B正相关。
lift(A,B) < 1, 表示A, B负相关。
lift(A,B) = 1,表示A,B无关系。
离群点挖掘
离群点
离群点代表着数据集中少数“与众不同”的点。
意义
发现与大部分其他对象显著不同的对象,大部分数据挖掘方法都将这种差异信息视为噪声而丢弃。然而在一些应用中,罕见的数据可能蕴含着更大的研究价值。离群点挖掘就是分析数据并及时发现异常,比如:及时发现欺诈行为并采集必要措施,从而避免损失!
应用
- 欺诈检查
- 天机预报
- 公共安全
- 医疗
- 入侵检测
- 电子商务
研究的主要问题
离群点挖掘就是通过某种方法找出数据集中“与众不同”的数据。
定义:如何定义和度量离群点。
方法:①基于统计的方法。②基于距离的方法。③基于密度的方法。
基于距离的方法
离群点定义:一个点远离数据集中大部分点,就认为它是离群点。
离群点挖掘:定义一种度量方式,找出远离数据集中大部分点的数据点。
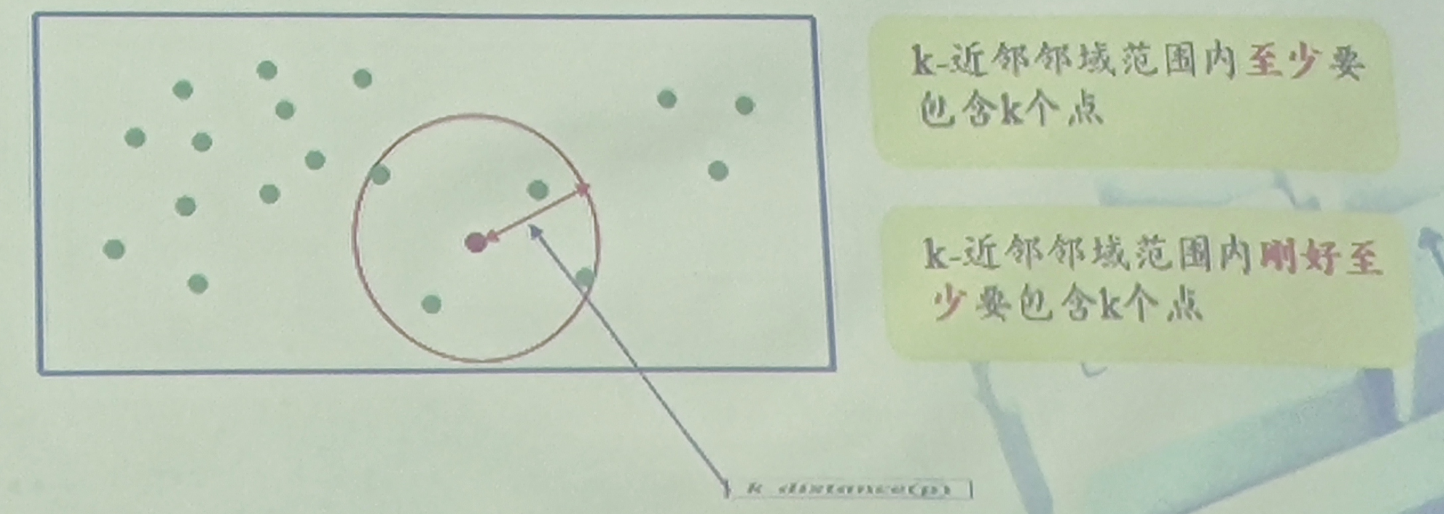

基于相对密度的方法
