常用命令
查看容器的挂载目录
1 | docker inspect 容器名 | grep Mounts -A 20 |
查看所有容器
1 | docker ps -a |
查看所有镜像
1 | docker images |
给镜像创建标签
1 | docker tag 镜像 新标签 |
进入容器
1 | docker exec -it 容器名或id /bin/bash |
重命名容器
1 | docker rename 原容器名 新容器名 |
查看容器信息
1 | docker inspect 容器名(返回回key/value json格式数据) |

拷贝容器里的文件到宿主机
1 | docker cp 容器名:容器里文件路径 宿主机路径 |
镜像搜索
1 | docker search [OPTIONS] TERM |

- STARS:星级(星级越高,代表镜像质量越高)
- OFFICIAL:是否官方
- AUTOMATED:是否为docker自动化构建
查看容器ip
1 | docker inspect --format='{{.NetworkSettings.IPAddress}}' 容器id |
镜像拉取
1 | docker pull [OPTIONS] NAME[:TAG|@DIGEST] |
镜像上传
注:执行push前需要执行login进行用户身份认证
1 | docker push [OPTIONS] NAME[:TAG] |
搭建私有仓库
私有仓库搭建与配置
- 拉取私有仓库镜像。
1 | docker pull registry |
- 启动私有仓库容器。
1 | docker run -di --name=registry -p 5000:5000 registry |
- 打开浏览器 输入地址
ip:5000/v2/_catalog看到{"repositories":[]}表示私有仓库搭建成功并且内容为空。 - 修改daemon.json。
1 | vi /etc/docker/daemon.json |
- 添加私有仓库地址,让 docker信任私有仓库地址,保存退出。
1 | {"insecure-registries":["ip:5000"]} |
- 重启docker 服务。
1 | systemctl restart docker |
镜像上传至私有仓库
- 标记镜像为私有仓库的镜像
1 | docker tag 镜像 ip:5000/镜像tag |
- 再次启动私服容器
1 | docker start registry |
- 上传标记的镜像
1 | docker push ip:5000/镜像tag |
示例
创建并运行MySQL容器
1 | docker run |
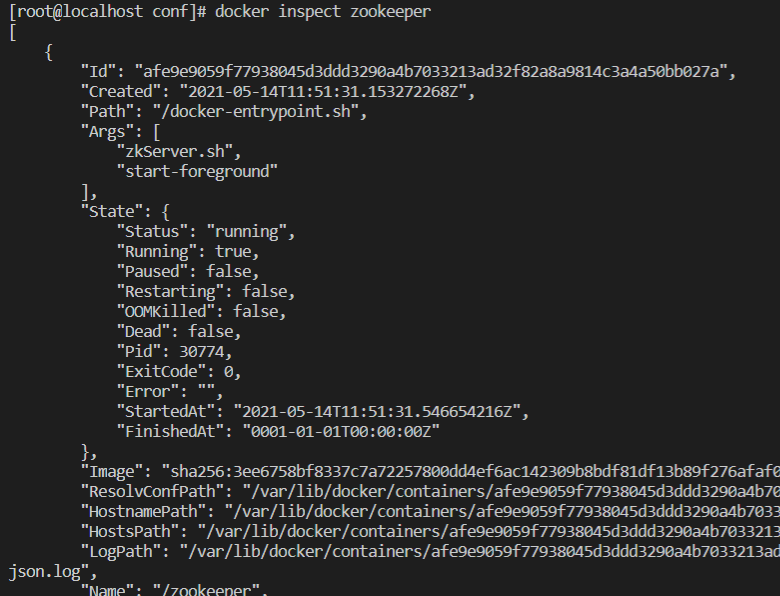
创建zookeeper容器
1 | docker run --name zookeeper --restart always -d -v /usr/local/docker_container_config/zookeeper/conf/:/conf/ -p 2181:2181 zookeeper |
创建kafka容器
1 | docker run -d --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.38.128:2181/kafka -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.38.128:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime -v /usr/local/docker_container_config/kafka/config/server.properties:/opt/kafka/config/server.properties wurstmeister/kafka |
组件工具
- docker-Machine
负责实现对 Docker 运行环境进行安装和管理,特别在管理多个 Docker 环境时,使用 Machine 要比手动管理高效得多。
- docker-swarm
提供 Docker 容器集群服务,是docker官方对容器云生态进行支持的核心方案。使用它,用户可以将多个 Docker 主机抽象为大规模的虚拟 Docker 服务,快速打造一套容器云平台。
- docker-compose
主要用于docker容器在集群中快速部署。负责实现对基于 Docker器的多应用服务的快速编排,利用docker-compose,从用户可以自定义哪个容器运行在哪个应用。与此同时,docker-compose也支持热部署,而且可以根据负载情况随时扩展。
DockerFile
Dockerfile是一个文本文件,存储Docker可以读懂的脚本指令,在这个脚本文件中记录着用户“创建”镜像过程当中需要执行的所有命令。当Docker 读取并执行Dockerfile 中所定义的命令时,这些命令将会产生一些临时文件层(AUFS所使用的文件层)。当Dockerfile所有命令都成功执行完之后,Docker 会记录执行过程中所用到的所有文件层,并且会用一个名称来标记这一组文件层。这一组文件层,就被称之为镜像(镜像指的是一组特定的文件层)。Docker中镜像的构建过程,就是 Docker 执行Dockerfile中所定义命令而形成这组文件层的过程。Docker中所有的容器都是基于镜像而创建的,而所有的镜像又都是通过Dockerfile而形成的。
内置命令

Dockerfile示例
1 | FROM buildpack-deps:wheezy-scm |
AUFS
AUFS(Advanced Multi Layered Unification Filesystem 高级多层次统一文件系统)是一个堆栈式联合文件系统。它可以将不同地方的目录挂载到同一个虚拟文件系统之中,并且形成“文件层”。在将不同目录挂载到同一文件系统下时,还可以给不同目录设定只读、只写和写出三种权限。AUFS在挂载目录时,会严格按照先基础目录(父文件层)再增量目录(子文件层)的顺序进行挂载。(docker通过AUFS实现镜像文件层、数据共享)所有目录都挂载完之后,AUFS 会再挂载一个可读可写的目录,而以后所有的写操作都会体现在此目录中(docker容器的修改操作都在这一层)。
深入
LXC
LXC(Linux container)是整个Docker运行的基础。众所周知,CPU、内存、IO、网络等都称之为系统资源,而Linux内核有一套机制来管理其所拥有的这些资源,这套机制的核心被称之为CGroups和Namespaces。
CGroups(Controller Groups)
为资源管理提供了一个统一框架,可以把系统任务及其子任务整合(或分隔)到按资源等级而划分的不同任务组内,并且对这些任务组实施不同的资源分配方案。可以限制、记录、调整进程组所使用的物理资源(包括CPU、memory、I/O等)。如:使用CGroups可以给某项进程组多分配一些CPU使用周期。同样也可以通过CGroups限制某项进程组可使用的内存上限。同时CGroups 也具有记录物理资源使用情况的功能,比如 CGroups调用 cpuacct子系统就可以记录每个进程所使用的内存数量、CPU时间等数据。正因为Linux有了CGroups资源管理机制,内核虚拟化才变成了可能。
CGroups机制中四个重要概念
- 任务( task):一个任务对应宿主机环境当中的一个进程。
- 子系统(subsystem):每一个子系统是对某一项具体物理资源的控制器。例如,cpu子系统就是对CPU资源的控制,内存子系统就是对内存资源的控制。
- 控制组(control group):cgroups当中最基本的控制单元。一个group包含若干个任务(对应宿主环境的进程),并且此 group也会包含若干子系统,用来控制group 内的任务在指定子系统上面的资源使用。
- 层级树(hierarchy):cgroups的调度单位,由一个或多个group组成的树状结构。每个hierarchy通过绑定对应的子系统进行资源调度,同时子节点继承父节点的属性。整个系统可以有多个hierarchy。
cgroups共有10个子系统:(执行
ls /sys/fs/cgroup/命令查看)
- blkio:为块设备(比如磁盘,固态硬盘,USB等)设定IO限制。
- cpu: 对CPU资源的控制。
- cpuacct:为cgroup中任务生成CPU 资源使用报告。
- cpuset:在多CPU系统中,为cgroup中的任务分配独立CPU和内存节点。
- devices:设置任务对物理设备的访问权限。
- freezer:挂起或者恢复cgroup 中的任务。
- memory:设定cgroup中任务使用的内存限制,同时生成任务的内存资源使用报告。
- net_cls:使用等级识别符(classid)标记网络数据包,同时使用Linux流量控制程序(tc)识别从具体cgroup 中生成的数据包。
- net_prio:对应用程序设置网络传输优先级,类似于socket选项的SO_PRIORITY。
- HugeTLB:HugeTLB页的资源控制功能。
Namespaces
一个重要的资源隔离机制。Namespaces 将进程、进程组、IPC(Inter-Process Communication,进程间通信资源:管道、消息队列……)、网络、内存等资源都变得不再是全局性资源,而是将这些资源从内核层面属于某个特定的Namespace。在不同的Namespace之间,这些资源是相互透明、不可见的。比如说,A用户登录系统后,可以查看到B用户的进程PID。虽说A用户不能杀死B用户的进程,但A和B却能相互感知。但假如A用户在Namespace-A中,B用户在Namespace-B中,虽然A和B仍然共存于同一个Linux操作系统当中,但A却无法感知到B。在这种情况下,Linux内核不但将Namespace相互隔离,而且将所分配的资源牢牢固定在各自空间之中。
注:每个 Linux 系统最初仅有一个命名空间。 所有系统资源(诸如文件系统、 用户 ID、 网络接口等) 属于这一个命名空间。
IPC Namespace
Linux系统进程间通讯主要包括:信号量、消息队列和共享内存,对于一个资源隔离的容器来说,容器内的进程只能访问主机分配给它的资源,IPC Namespace允许容器内所有进程通过全局唯一的32位标识符访问共享资源。使容器内部的进程通信,对于宿主机来说,就是相同PID的进程通信。
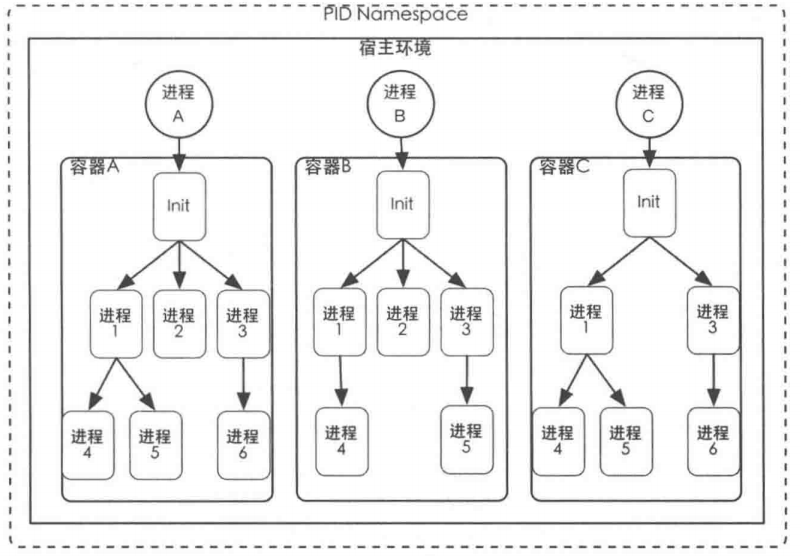
PID Namespace
容器之间的进程树相互不可见。通过PID Namespace,为容器创建了独立的进程资源,每个容器中都会有一个进程号计数器,容器内所有的进程号都会重新编号。宿主机的内核会维护各个容器中的进程树,在树最顶端的进程号为l,也就是Init进程。此进程会作为容器内其他所有进程的父进程来执行容器环境的初始化工作。但此Init进程毕竟不是实际操作系统中的 Init进程,在宿主机环境中,只是个普通进程。所以容器中的Init进程其实是一个伪 Init进程,它无法像真正的 Init 进程那样“守护”整个容器操作环境。当Init进程下面所有的子进程都退出后,它也就无可避免地需要退出。而这也就是每个容器启动时都需要指定一个不可退出的进程作为CMD的原因。同时Init进程作为容器中所有进程的父进程,还肩负着关闭和销毁容器的责任。因为借助于PID Namespace在容器中所产生的进程树,处于树顶点的 Init进程可以看到容器中所有的子进程,并且可以通过信号量来影响子进程的行为。所以 Docker CLI 中的Stop或者Kill 命令的本质,就是向容器中的Init进程发送SIGSTOP信号或者SIGKILL信号。一旦容器处于顶点的Init进程被销毁,那么和其处于同一个 PID Namespace的所有进程都将会接收到内核发送的SIGSTOP或者SIGKILL信号而被销毁。
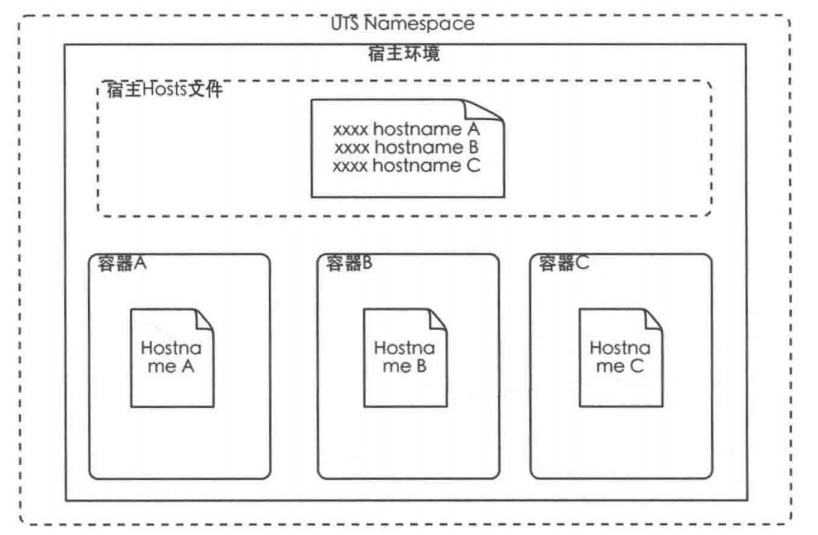
UTS Namespace
PID Namespace使容器拥有独立进程树,仅仅只能在宿主环境层面可以被视为独立节点。UTS Namespace使容器在网络层面被设为一个独立节点。它为每个容器设置了容器主机名和容器域名,因为这两个属性在每个容器当中都是独立且唯一的,因此每个容器在网络中都可被设为单独节点,拥有了独立主机名和域名资源,而非宿主机环境中的单独进程。
Network Namespace
为每个容器隔离网络资源。在 Linux系统中一个物理设备最多只能被包括在一个Network Namespace中,但我们所创建的容器却不止一个。Docker为每个容器的Network创建一对虚拟网络设备,一个名为eth0,放置到容器当中;另外一个名为vethN,放置到宿主机环境当中。这样从一个设备中流入数据,就可以从相对应的另外一个设备中读取到数据。虽然从宿主机内核层面来看,其实这两个网卡只是管道的两端;但从容器中来看,这就是两块实际的网卡。通过这种方式,可以达到容器和内核之间数据流通的目的。但为了达到不同容器可以作为网络单独节点进行数据交互的目标,Docker在Network Namespace中还为每个容器设置了IP路由表。宿主机环境此时就充当了路由器的角色,因此毫不相干的两个容器就可以通过其内部的”网卡”互通数据。
User Namespace
docker通过User Namespace隔离了所有与用户相关的资源,包括用户ID、用户组ID、用户权限。但无论容器中的用户怎么变,始终对应的是宿主机环境中所创建容器的用户,而且这种关联关系通过/proc/[pid]/uid_map和/proc/[pid]/gid_map这两个文件予以保存。
Mount Namespace
docker通过 Mount namespace为每个容器分配了独立的文件系统。因为在 Mount Namespace当中,可以通过隔离文件挂载点的方式提供隔离的文件系统,因此,Docker为每个容器创建一个其独有的目录,并且将此容器所依赖的镜像文件层按照先父后子的顺序,逐层挂载到此目录当中。隔离完成之后,不同的Mount Namespace之间的数据互不影响。同时,Docker 会将当前目录设置为read-only模式,对此目录所做出的所有写操作都将体现到另外一个目录,而这个目录也就是writable文件层。
而LXC就是基于Linux内核通过调用CGroups 和Namespaces,来实现容器轻量级虚拟化的一项技术,与此同时,LXC也是一组面向Linux内核容器的用户态API接口。用户通过LXC提供的资源限制和隔离功能,可以创建一套完整并且相互隔离的虚拟应用运行环境。Docker就是采用LXC技术来创建容器的工具, 因此LXC是Docker运行的基础,而 docker则是LXC的杀手级应用。
体系结构
- Docker Daemon:负责维护 Docker运行的守护进程,担负资源管理、任务调度等多项功能。
- Docker Image(镜像):属于静态文件系统
- Docker Container(容器):基于Image真正提供应用服务的计算单元。
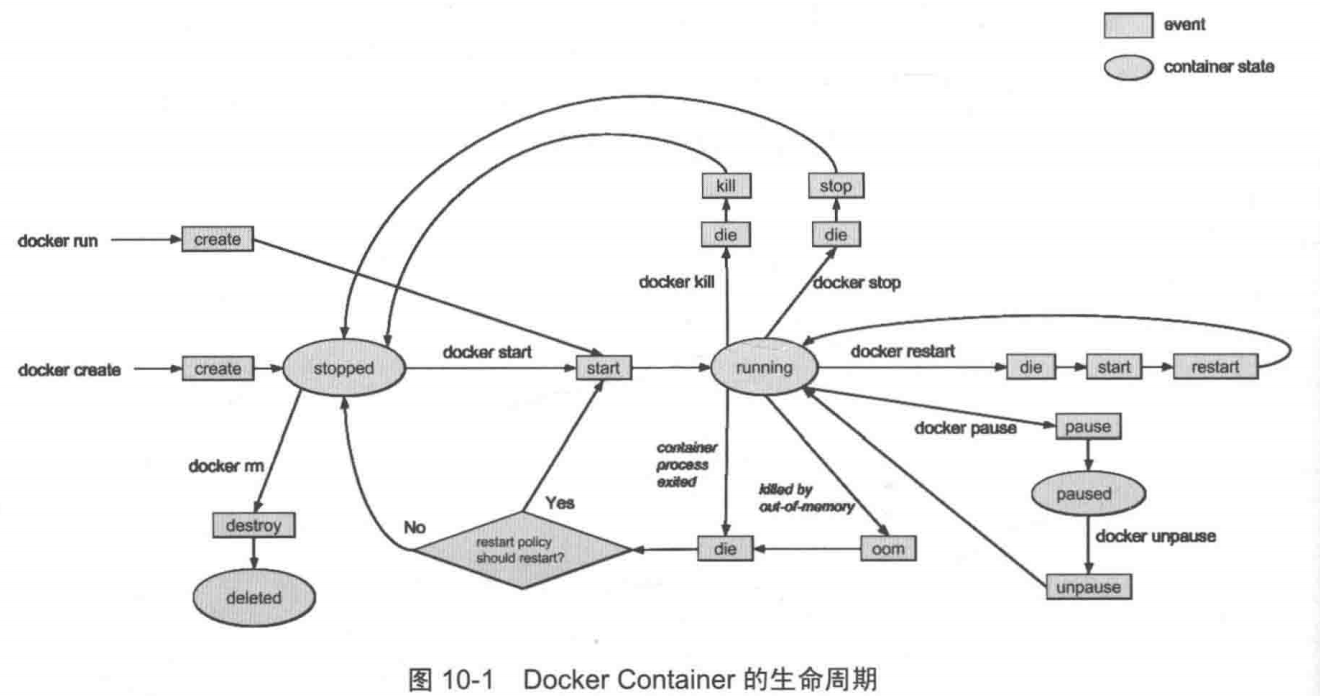
三者关系: Container 基于Image被 Daemon创建和管理,来实现提供服务的功能。因为Container负责提供服务,所以处于核心位置。因而当我们谈论到Docker生命周期时,更多的指的是Docker Container的生命周期。
Docker Container的生命周期
Docker Daemon主要任务
- 负责任务调度,它需要将客户端传来的命令请求转化为特定的任务。
- 负责维护镜像数据。一个完整的镜像由许多的子文件层组成,而这个镜像的依赖关系就是由 Daemon来维护的。
- 负责容器虚拟化。虚拟化是一个较大的概念,具体来说就是资源分配和资源隔离。
- 负责容器生命周期。Daemon需要根据用户指令和容器自身状态来维护容器的生命周期。
四项任务关系图
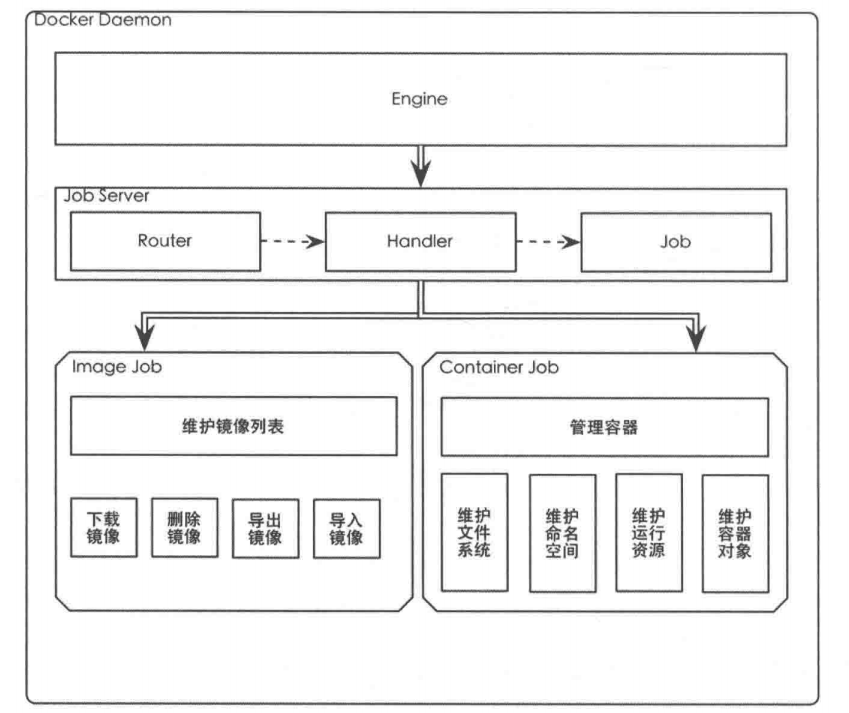
Engine模块用来监听来自客户端的Restful API请求,Engine既可以通过unix:/来监听本地 socket 文件(默认是Docker.sock),也可以通过tcp:/l的方式来监听某一个端口。当然也可以选择两种方式同时监听。
Engine模块会将接收到的命令请求转化为具体的Job,而转化的依据就是存放在Daemon当中的API路由表。每一个API都有唯一与之相对应的Handler函数,在此Handler函数中,会有一系列的逻辑来处理客户端请求。而负责处理请求的逻辑函数,在 Docker Daemon当中就以Job的形式运行。
Router、Handler和Job这三项共同组成了JobServer。而Engine每接收到一次来自于客户端的处理请求,就会生出一个 JobServer。当Job完成作业,并将数据返回给客户端之后,此JobServer也会随之销毁。
在Docker Daemon中,只有两种Job类型:Image Job和 Container Job。Image Job重点在于通过 AUFS 文件系统来维护镜像数据,而 Container Job则侧重于管理资源。
Docker Daemon通过LXC管理资源的过程
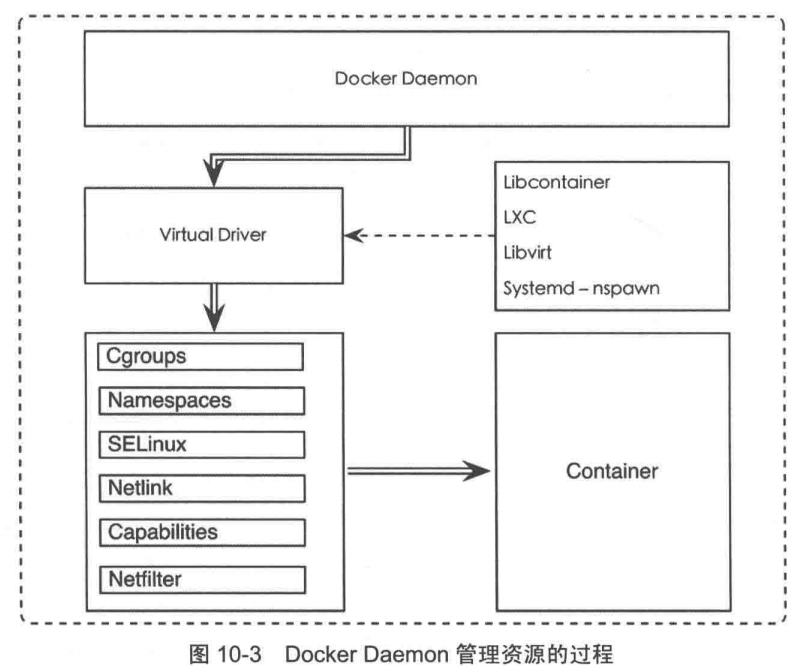
Daemon并不参与资源分配和隔离的工作,这些工作都是由虚拟化驱动来完成的。充当虚拟化驱动的有LXC、Libcontainer、Libvirt和 nspawn。(Libcontainer是Docker自行开发用于管理资源的驱动库,Docker最初使用LXC,后面替换为libcontainer。)Daemon通过驱动库来管理Cgroups、namespaces、SELinux等各个组件,然后再基于所创建的资源使用方案产生一个可用的容器。
docker客户端与服务端交互大致流程
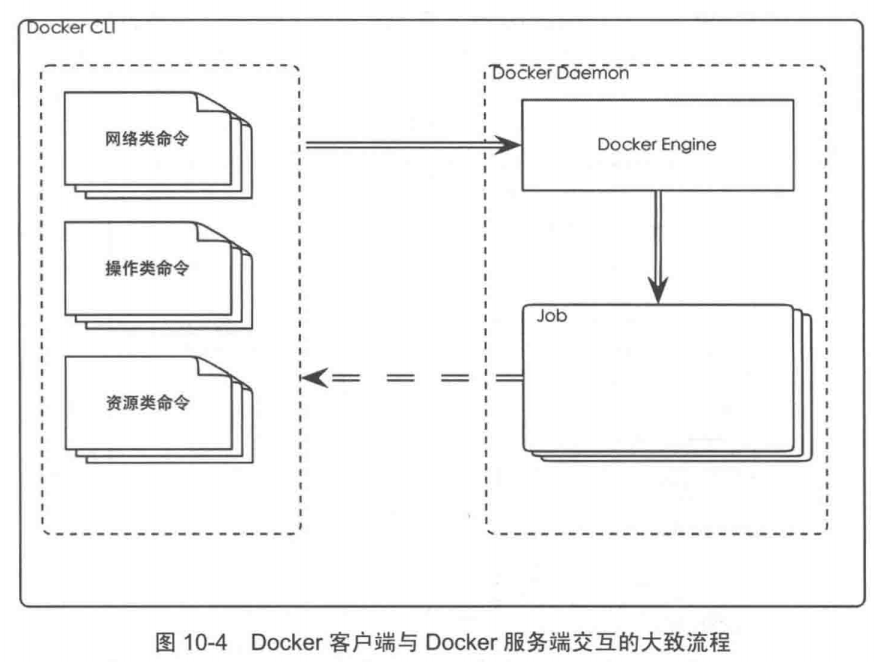
每一个 Docker CLI都必须通过Rest API的方式调用Docker Daemon完成某项特定的工作。
参考
书:《Docker全攻略》
问题记录
修改容器配置后无法启动
1 | # 查看日志 |

