各数据类型内存占用大小
| 类型 | 大小 |
|---|---|
bool |
1个字节 |
intN, uintN, floatN, complexN |
N/8个字节(例如float64是8个字节) |
int, uint, uintptr |
1个机器字 |
*T |
1个机器字 |
string |
2个机器字(type,value) |
[]T |
3个机器字(data,len,cap) |
map |
1个机器字 |
func |
1个机器字 |
chan |
1个机器字 |
interface |
2个机器字(type,value) |
fmt.Printf转换字符(动词:verb)
1 | %d 十进制整数 |
switch
case 后默认break,可用fallthrough关键字接着执行下一个case(无论其值是否符合)
1 | switch coinflip() { |
内置函数len
len函数可以返回一个字符串中的字节数目(不是rune字符数目),索引操作s[i]返回第i 个字节的字节值,i必须满足0 ≤ i< len(s)条件约束。
1 | str := "12中3" |
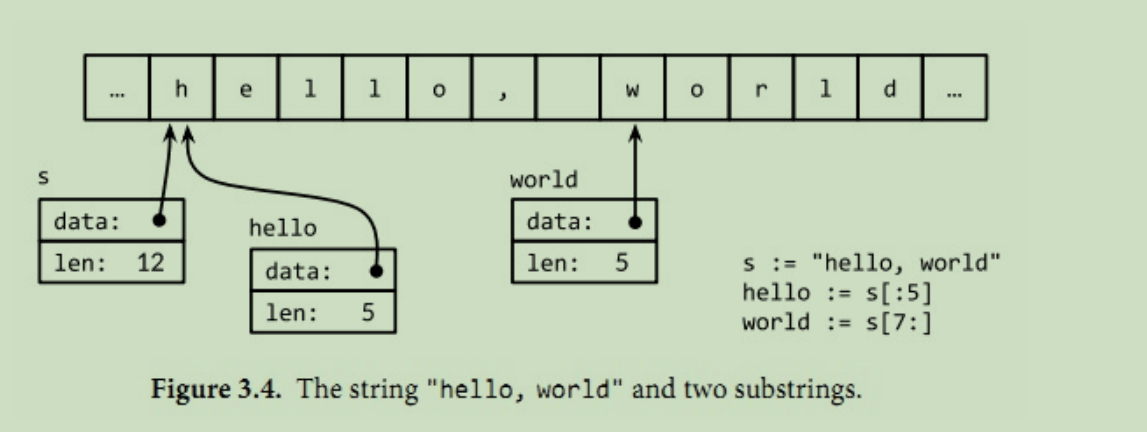
字符串
字符串的值是不可变的,数据安全的,一个字符串和两个子串共享相同的底层数据,如下。
函数声明
函数声明包括函数名、形式参数列表、返回值列表(可省略)以及函数体
1 | //给出4种方法声明拥有2个int型参数和1个int型返回值的函数 |
反射中的Type与Kind
Type是类型,Kind是类别,Type与Kind可能相同,也可能不同。
- var num int = 10, num的Type和Kind都是int。
- var people = Student{},people的Type是 包名.Student,Kind是struct。
常用指令
go env 查看环境配置
go version 查看当前go版本
go get [param] packages 拉取远程依赖包
1 | # 参数介绍 |
go build
编译命令行参数指定的每个包。如果包是一个库,则忽略输出结果;这可以用于检测包是可以正确编译的。如果包的名字是main, go build 将调用链接器在当前目录创建 一个可执行程序;以导入路径的最后一段作为可执行程序的名字。默认情况下, go build 命令构建指定的包和它依赖的包,然后丢弃除了最后的可执行文件之外所有的中间编译结果。
go install
go install 命令 和 go build 命令很相似,但是它会保存每个包的编译成果,而不是将它们都丢弃。被编译的包会被保存到$GOPATH/pkg目录下,目录路径和 src目录路径对应,可执行 程序被保存到$GOPATH/bin目录。
注: go install 命令和 go build 命令都不会重新编译没有发生变化的包。
go run
是go build 与执行可执行文件的结合,即构建并运行
1 | $ cat quoteargs.go |
go test
go test命令是一个按照一定的约定和组织来测试代码的程序。在包目录内,所有 以 _test.go 为后缀名的源文件在执行go build时不会被构建成包的一部分,它们是go test测 试的一部分。 在 *_test.go 文件中,有三种类型的函数:测试函数、基准测试(benchmark)函数、示例函数。一个测试函数是以Test为函数名前缀的函数,用于测试程序的一些逻辑行为是否正确; go test命令会调用这些测试函数并报告测试结果是PASS或FAIL。基准测试函数是以 Benchmark为函数名前缀的函数,它们用于衡量一些函数的性能;go test命令会多次运行基准函数以计算一个平均的执行时间。示例函数是以Example为函数名前缀的函数,提供一个由编译器保证正确性的示例文档。go test命令会遍历所有的 *_test.go 文件中符合上述命名规则的函数,生成一个临时的main 包用于调用相应的测试函数,接着构建并运行、报告测试结果,最后清理测试中生成的临时文件。
1 | # 测试函数 |
模块管理
go mod
1 | download //下载模块到本地缓存,具体可以通过命令go env查看,其中环境变量GOCACHE就是缓存的地址,如果该文件夹的内容太大,可以通过命令go clean -cache |
按需编译
有些包可能需要针对不同平台和处理器类型使用不同版本的代码文件,以便于处理底层的可 移植性问题或为一些特定代码提供优化。如果一个文件名包含了一个操作系统或处理器类型 名字,例如net_linux.go或asm_amd64.s, Go语言的构建工具将只在对应的平台编译这些文 件。还有一个特别的构建注释参数可以提供更多的构建过程控制。例如,文件中可能包含下面的注释:
1 | // +build linux darwin |
下面的构建注释则表示不编译这个文件:
1 | // +build ignore |
GMP
M(Machine):工作线程。 执行系统的最基本单位goroutine,存储了goroutine的执行stack信息、goroutine状态以及goroutine的任务函数等。
P(Processor),是一个抽象的概念,表示逻辑CPU,代表线程M的执行的上下文,调度goroutine。当P有任务时需要创建或者唤醒一个系统线程来执行它队列里的任务。所以P/M需要进行绑定,构成一个执行单元。P的最大作用是其拥有的各种G对象队列、链表、cache和状态。P的数量也代表了golang的执行并发度,即有多少goroutine可以同时运行,可通过GOMAXPROCS限制同时执行用户级任务的操作系统线程。可以通过runtime.GOMAXPROCS进行指定。
G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
G协程栈初始分配大小为2k,最大值由操作系统限制,64位为1GB,32位为250MB,以2倍形式增长。
1
2
3
4
5
6
7
8
9
10@runtime/stack.go:72
// The minimum size of stack used by Go code
_StackMin = 2048
@runtime/proc.go:115
if sys.PtrSize == 8 {
maxstacksize = 1000000000
} else {
maxstacksize = 250000000
}注:
Linux线程默认大小为8M。windows线程栈默认大小为1M。操作系统线程栈大小可在创建线程(CreateThread)时指定,不可在程序执行过程中动态修改。
GMP关系
M必须拥有P才可以执行G中的代码,P含有一个包含多个G的队列,P可以调度G交由M执行。其关系如下图所示:
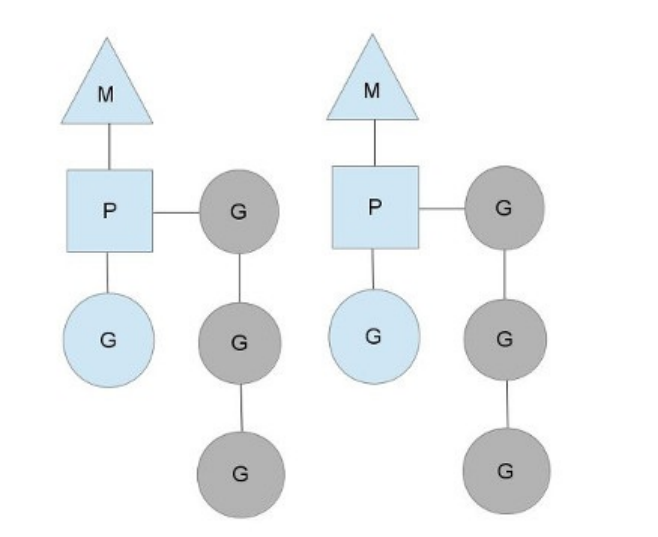
图中M是交给操作系统调度的线程,M持有一个P,P将G调度进M中执行。P同时还维护着一个包含G的队列(图中灰色部分),可以按照一定的策略将不能的G调度进M中执行。
P的个数在程序启动时决定,在Go1.5之后被默认设置CPU的核数,而之前则默认为1。由于M必须持有一个P才可以运行Go代码,所以同时运行的 M个数,也即线程数一般等同于CPU的个数,以达到尽可能的使用CPU而又不至于产生过多的线程切换开销。
Goroutine调度策略
队列轮转
上图中可见每个P维护着一个包含G的队列,不考虑G进入系统调用或IO操作的情况下,P周期性的将G调度到M中执行, 执行一小段时间,将上下文保存下来,然后将G放到队列尾部,然后从队列中重新取出一个G进行调度。 除了每个P维护的G队列以外,还有一个全局的队列,每个P会周期性的查看全局队列中是否有G待运行并将期调度到M 中执行,全局队列中G的来源,主要有从系统调用中恢复的G。之所以P会周期性的查看全局队列,也是为了防止全局队 列中的G被饿死。
系统调用
上面说到P的个数默认等于CPU核数,每个M必须持有一个P才可以执行G,一般情况下M的个数会略大于P的个数,这多 出来的M将会在G产生系统调用时发挥作用。类似线程池,Go也提供一个M的池子,需要时从池子中获取,用完放回池 子,不够用时就再创建一个。
当M运行的某个G产生系统调用时,如下图所示:
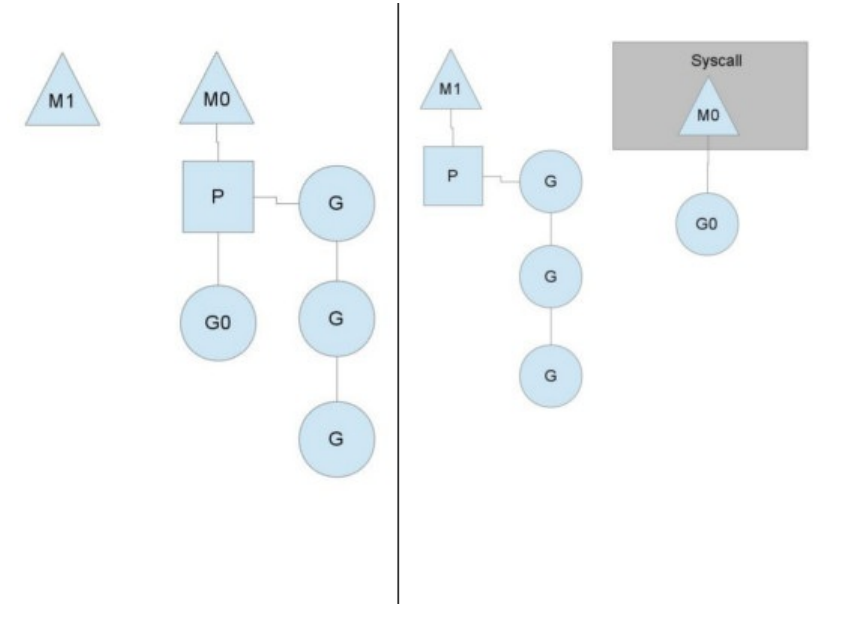
如图所示,当G0即将进入系统调用时,M0将释放P,进而某个空闲的M1获取P,继续执行P队列中剩下的G。而M0由于 陷入系统调用而进被阻塞,M1接替M0的工作,只要P不空闲,就可以保证充分利用CPU。 M1的来源有可能是M的缓存池,也可能是新建的。当G0系统调用结束后,跟据M0是否能获取到P,将会将G0做不同的 处理:
- 如果有空闲的P,则获取一个P,继续执行G0。
- 如果没有空闲的P,则将G0放入全局队列,等待被其他的P调度。然后M0将进入缓存池睡眠。
工作量窃取
当P中G全部执行完,会去查询全局队列,若全局队列中也没有G,而另一个M中除了正在运行的G 外,队列中还有3个G待运行(如下图所示)。此时,空闲的P会将其他P中的G偷取一部分过来,一般每次偷取一半。
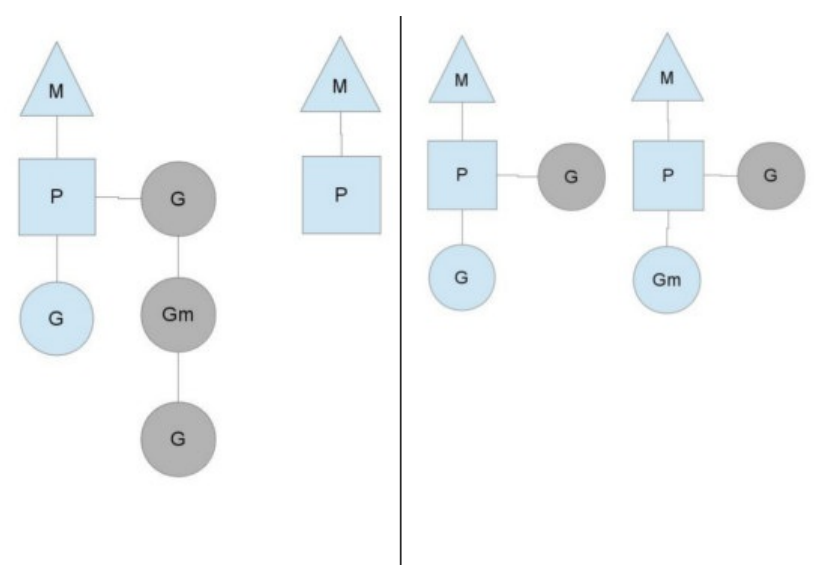
注:从全局队列(GQ)取的 G 数量符合下面的公式:n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))
m0和g0
m0
m0 表示进程启动的第一个线程,也叫主线程。它和其他的m没有什么区别,要说区别的话,它是进程启动通过汇编直接复制给m0的,m0是个全局变量,而其他的m都是runtime内自己创建的。 m0 的赋值过程,可以看runtime/asm_amd64.s 的代码。一个go进程只有一个m0。g0
首先要明确的是每个m都有一个g0,因为每个线程有一个系统堆栈,g0 虽然也是g的结构,但和普通的g还是有差别的,最重要的差别就是栈的差别。g0 上的栈是系统分配的栈,在linux上栈大小默认固定8MB,不能扩展,也不能缩小。 而普通g一开始只有2KB大小,可扩展。在 g0 上也没有任何任务函数,也没有任何状态,并且它不能被调度程序抢占。因为调度就是在g0上跑的。proc.go 中的全局变量 m0和g0
1 | var ( |
在 runtime/proc.go 的文件中声明了两个全局变量,m0表示主线程,这里的g0表示和m0绑定的g0,也可以理解为m0线程的堆栈,这两个变量的赋值是汇编实现的。
调度流程图
1 | +-------------------- sysmon ---------------//------+ |
上图基本上概括了整个调度流程,go 关键字创建了G,并插入到P的本地队列或者全局队列,线程M从各个队列中或者从别的P中得到G, 切换到G的执行栈上并执行G上的任务函数,调用goexit做清理工作并回到调度程序,调度程序重新找个可执行的G,并执行,如此反复。 其中 sysmon 会监控整个调度系统,如果某个G长时间占用cpu,会被标记为可抢占。
work-stealing
Go scheduler 的职责是将所有处于 runnable 的 goroutines 均匀分布到在 P 上运行的 M。当一个 P 发现自己的 LRQ 已经没有 G 时,并且这时 GRQ 也没有 G 了。会从其他 P “偷” 一半 G 来运行。这被称为 Work-stealing,Go 从 1.1 开始实现。
参考
《Go专家编程》
内存模型
包初始化 init函数。
如果一个包 p 导入了包 q,那么 q 的 init 函数完成happens before p 的 init 。main.main 函数的开始happens after 所有的 init 函数完成。
创建goroutine
创建goroutine happens before goroutine执行。
销毁goroutine
goroutine执行happens before goroutine的销毁。
锁
对任意的sync.Mutex或sync.RWMutex变量l和n < m,n次调用l.Unlock()先行发生于m次l.Lock()返回。
对于sync.RWMutex变量l,任意的函数调用l.RLock满足第n次l.RLock后发生于第n次调用l.Unlock,对应的l.RUnlock先行发生于第n+1次调用l.Lock。
Once
sync.Once对于 f() 的单个调用在所有的 once.Do(f) 返回之前发生。
channel
- 对一个channel的发送操作 happens-before 相应channel的接收操作完成。
- 关闭一个channel happens-before 从该Channel接收到最后的返回值0。
- 不带缓冲的channel的接收操作 happens-before 相应channel的发送操作完成。
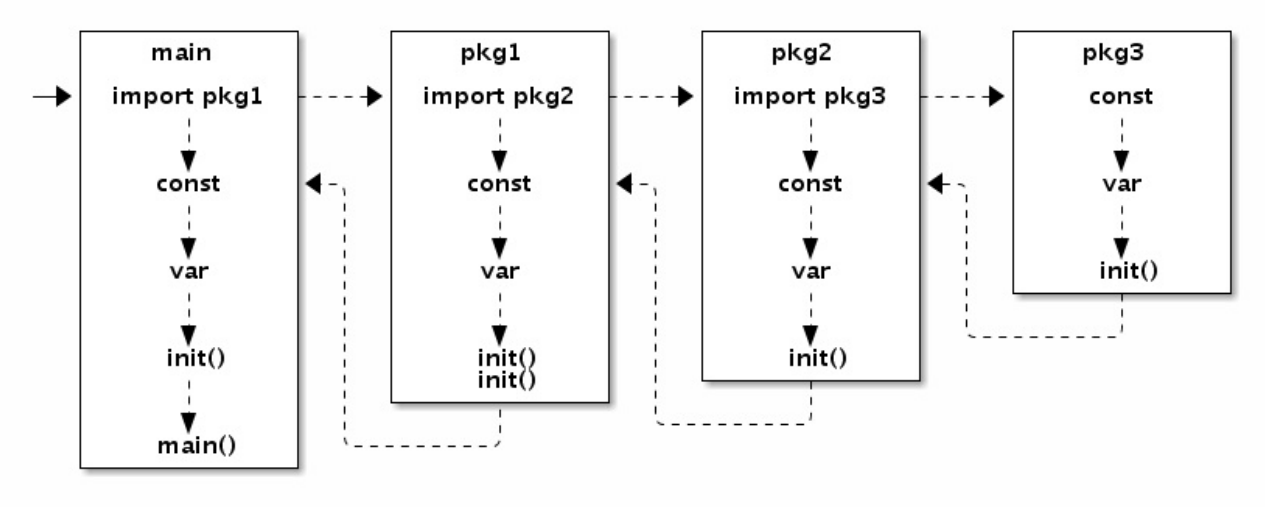
Go程序函数启动顺序
X86-64体系结构
X86其实是是80X86的简称(后面三个字母),包括Intel 8086、80286、80386以及80486等指令集合,因此其架构被称为x86架构。x86-64是AMD公司于1999年设计的x86架构的64位拓展,向后兼容于16位及32位的x86架构。X86-64目前正式名称为AMD64,也就是Go语言中GOARCH环境变量指定的AMD64。
X86/AMD架构图

内存布局
- text一般对应代码段,用于存储要执行指令数据,代码段一般 是只读的。
- 然后是rodata和data数据段,数据段一般用于存放全局的数据,其中rodata是只读的数据段。
- heap段用于管理动态的数据
- stack段用于管理每个函数调用时相关的数据。
寄存器
- 状态寄存器: FLAGS和指令寄存器IP寄存器
- 通用寄存器:AX、BX、CX、DX、SI、DI、BP、SP。
注:在 X86-64中又增加了八个以R8-R15方式命名的通用寄存器。因为历史的原因R0-R7并不是通用寄存器, 它们只是X87开始引入的MMX指令专有的寄存器。在通用寄存器中BP和SP是两个比较特殊的寄存器:其中BP用于记录当前函数帧的开始位置,和函数调用相关的指令会隐式地影响BP的值;SP则对应当前栈指针的位置,和栈相关的指令会隐式地影响SP的值;而某些调试工具需要BP寄存器才能正常工作。
Go汇编
Go汇编为了简化汇编代码的编写,引入了PC、FP、SP、SB四个伪寄存器。四个伪寄存器加其它的通用寄存器就是Go汇编语言对CPU的重新抽象,该抽象的结构也适用于其它非X86类型的体系结构。
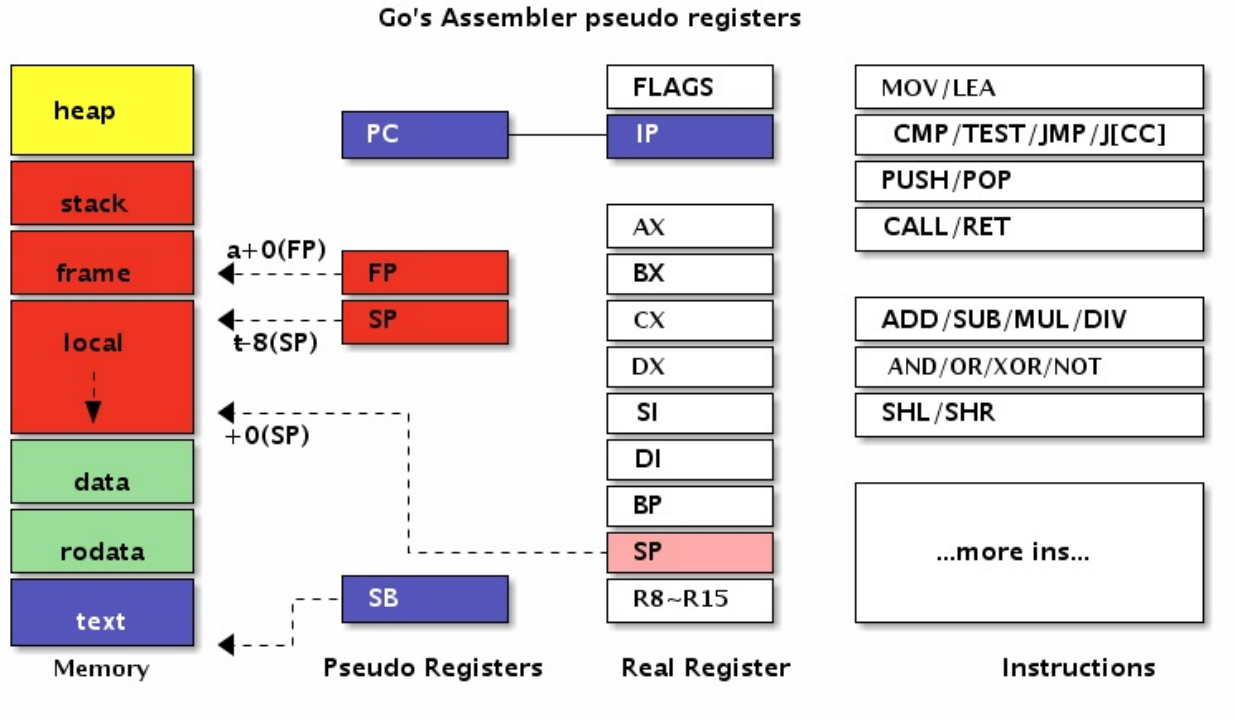
在AMD64环境,伪PC寄存器其实是IP指令计数器寄存器的别名。伪FP寄存器对应的是函数的帧指针,一般用来访问函数的参数和返回值。伪SP栈指针对应的是当前函数栈帧的底部(不包括参数和返回值部分),一般用于定位局部变量。伪SP是一个比较特殊的寄存器,因为还存在一个同名的SP真寄存器。真SP寄存器对应的是栈的顶部,一般用于定位调用其它函数的参数和返回值。当需要区分伪寄存器和真寄存器的时候只需要记住一点:伪寄存器一般需要一个标识符和偏移量为前缀,如果没有标识符前缀则是真寄存器。比如 (SP) 、 +8(SP) 没有标识符前缀为真SP寄存器, 而 a(SP) 、 b+8(SP) 有标识符为前缀表示伪寄存器。


