channel
src/runtime/chan.go:hchan 定义了channel的数据结构:
1 | type hchan struct { |
循环队列
chan内部实现了一个环形队列作为其缓冲区,队列的长度是创建chan时指定的。
下图展示了一个可缓存6个元素的channel示意图:
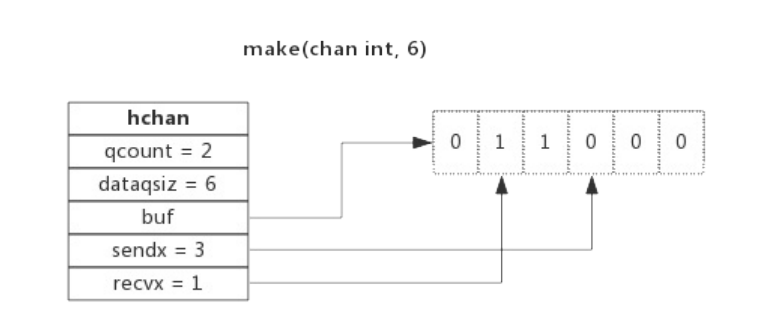
- dataqsiz指示了队列长度为6,即可缓存6个元素;
- buf指向队列的内存,队列中还剩余两个元素;
- qcount表示队列中还有两个元素;
- sendx指示后续写入的数据存储的位置,取值[0, 6);
- recvx指示从该位置读取数据, 取值[0, 6);
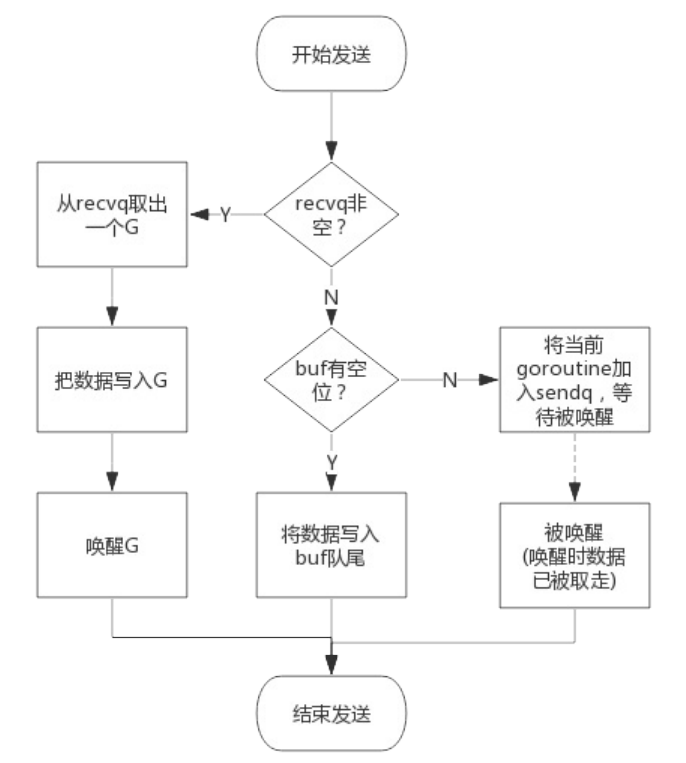
向channel中写数据
- 如果等待接收队列recvq不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从recvq取出G,并把数据
写入,最后把该G唤醒,结束发送过程;
如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
如果缓冲区中没有空余位置,将待发送数据写入G,将当前G加入sendq,进入睡眠,等待被读goroutine唤
醒;
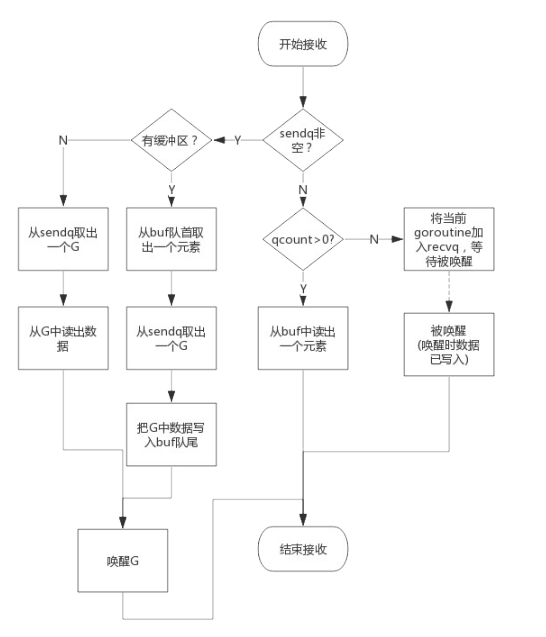
从channel读数据
- 如果等待发送队列sendq不为空,且没有缓冲区,直接从sendq中取出G,把G中数据读出,最后把G唤醒,结束
读取过程;
- 如果等待发送队列sendq不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把G中数据写入缓冲区尾
部,把G唤醒,结束读取过程;
如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;
将当前goroutine加入recvq,进入睡眠,等待被写goroutine唤醒;
注:关闭channel时会把recvq中的G全部唤醒。
panic出现的常见场景:
关闭值为nil的channel
关闭已经被关闭的channel
向已经关闭的channel写数据
slice
src/runtime/slice.go:slice 定义了Slice的数据结构:
1 | type slice struct { |
使用数组来创建Slice时,Slice将与原数组共用一部分内存。
如,语句 slice := array[5:7] 所创建的Slice,结构如下图所示:
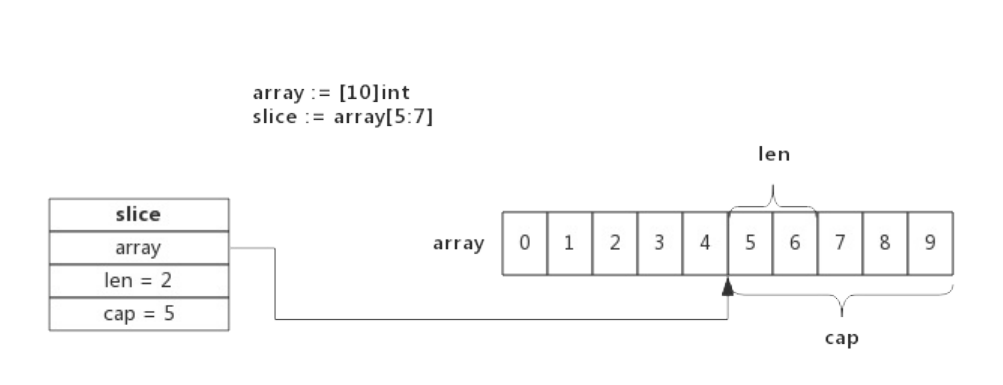
切片从数组array[5]开始,到数组array[7]结束(不含array[7]),即切片长度为2,数组后面的内容都作为切
片的预留内存,即capacity为5。
扩容规则
一般情况:
如果原Slice容量小于1024,则新Slice容量将扩大为原来的2倍;
如果原Slice容量大于等于1024,则新Slice容量将扩大为原来的1.25倍;
但实际上go还会进行内存规整,不一定安装此扩容规则。
详细参考https://golang.design/go-questions/slice/grow/
copy()
使用copy()内置函数拷贝两个切片时,会将源切片的数据逐个拷贝到目的切片指向的数组中,拷贝数量取两个切片长 度的最小值。例如长度为10的切片拷贝到长度为5的切片时,将会拷贝5个元素。 也就是说,copy过程中不会发生扩容。
数组或切片生成新的切片
slice[start :end :cap]生成的切片长度为end-start,容量为5。
slice[start:end] 方式生成的切片并没有指定切片的容量,实际上新切片的容量是从start开始直至slice的结束。
map
Golang的map使用哈希表作为底层实现,一个哈希表里可以有多个哈希表节点,也即bucket,而每个bucket就保存 了map中的一个或一组键值对。
map数据结构由 runtime/map.go/hmap 定义:
1 | type hmap struct { |
mapextra
1 | type mapextra struct { |
mapextra是一个为了优化bucket而设计的,当key或value是指针的时候,此时overflow和oldoverflow就不会被使用,只有nextOverflow会被使用,该字段保存了预先申请的溢出桶。在没有发生扩容的时候,一个桶或者说bmap的8个tophash都被使用完了,那么就要考虑使用逸出桶。
当key和value都没有指针的时候bucket的bmap的_type的ptrdata就是0,意味着该结构体是没有指针的,申请bmap内存的时候,会申请一个没有指针的span,这样会避免gc扫描该内存,会提高效率,但是bmap的最后一个内存块是确确实实存放指针的,所以用uintptr存储着该map的逸出桶的地址,但是由于没有指向下一个逸出桶,可能会被gc回收掉,所以就需要overflow存取指向该逸出桶的指针避免被gc回收掉。
bucket数据结构
runtime/map.go/bmap 定义:
1 | type bmap struct { |
- tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈 希值的高位存储在该数组中,以方便后续匹配。
- data区存放的是key-value数据,存放顺序是key/key/key/…value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
- overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。
一个bucket占272个字节
1 | type dmap struct { |
下图展示bucket存放8个key-value对:
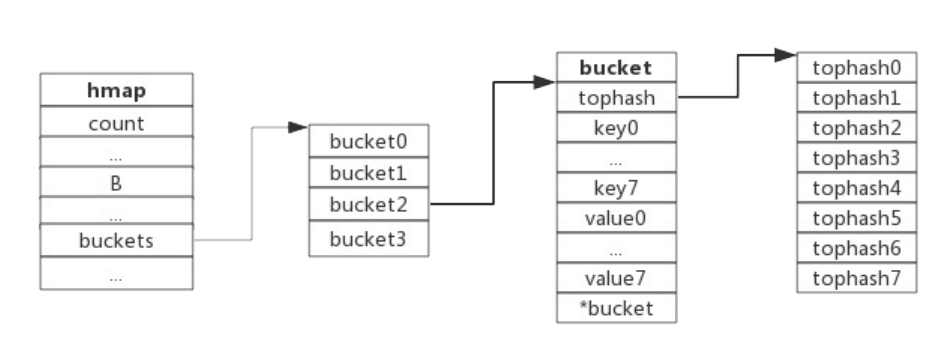
map的整体结构
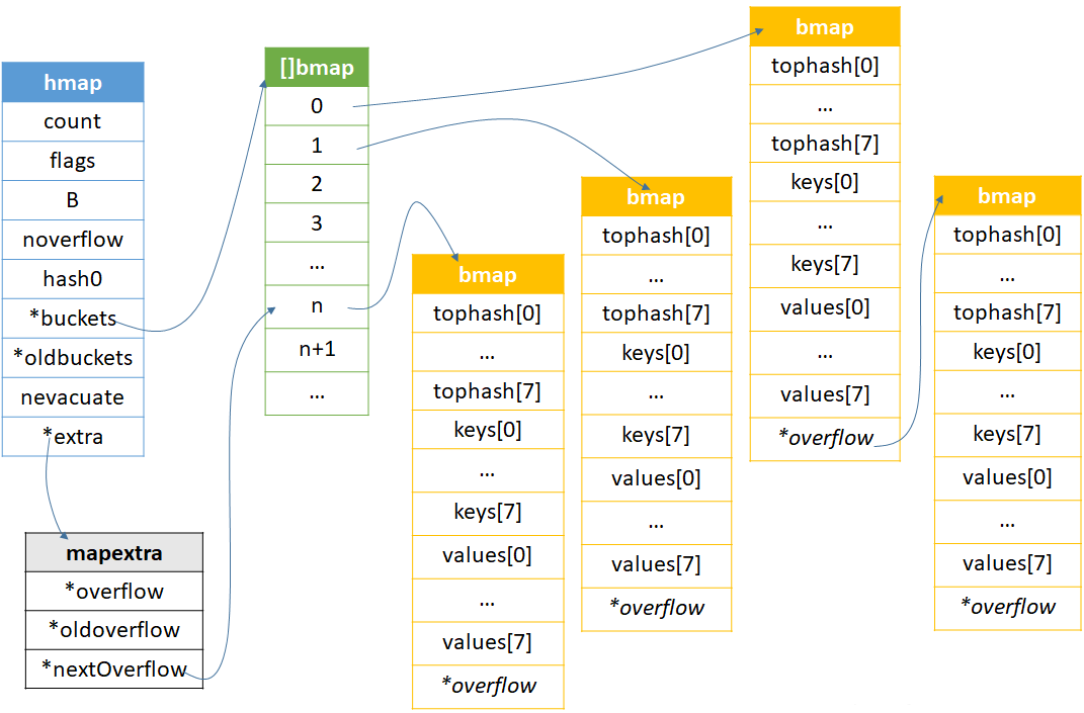
如果申请内存桶的时候有多余的溢出桶,那么mapextra的nextOverflow就会指向[]bmap其中的某块桶的地址,地址后之后的桶都是溢出桶。在一个桶装不下的时候,会去溢出桶拿桶然后bmap的overflow指向溢出桶。
hash冲突
Go使用链地址法来解决键冲突。由 于每个bucket可以存放8个键值对,所以同一个bucket存放超过8个键值对时就会再创建一个键值对,用类似链表的方式将bucket连接起来。 如下:
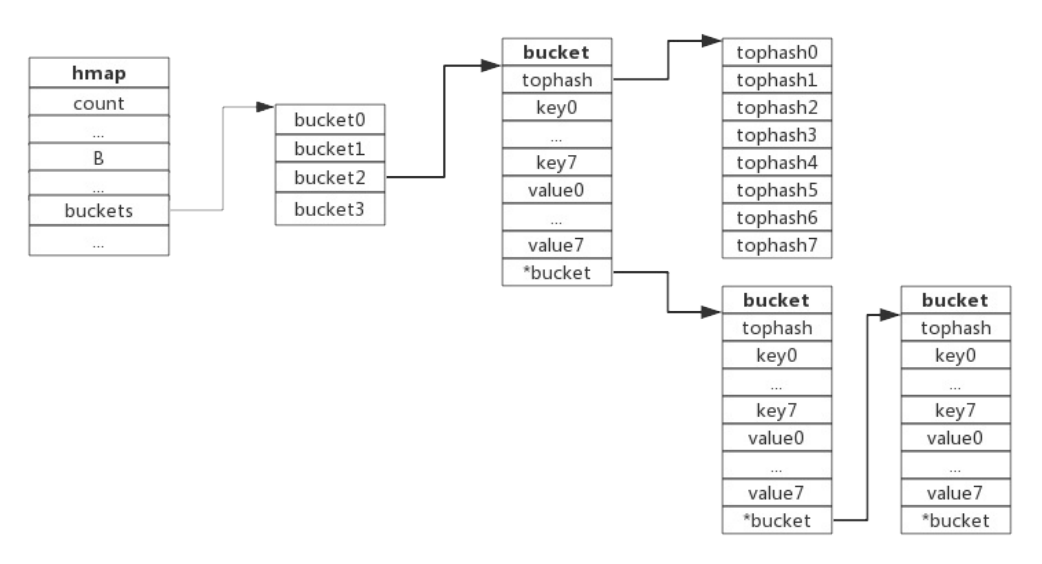
bucket数据结构指示下一个bucket的指针称为overflow bucket,意为当前bucket盛不下而溢出的部分。
负载因子
负载因子用于衡量一个哈希表冲突情况,公式为:
1 | 负载因子 = 键数量/bucket数量 |
例如,对于一个bucket数量为4,包含4个键值对的哈希表来说,这个哈希表的负载因子为1. 哈希表需要将负载因子控制在合适的大小,超过其阀值需要进行rehash,也即键值对重新组织:
- 哈希因子过小,说明空间利用率低
- 哈希因子过大,说明冲突严重,存取效率低
每个哈希表的实现对负载因子容忍程度不同,比如Redis实现中负载因子大于1时就会触发rehash,而Go则在在负载 因子达到6.5时才会触发rehash,因为Redis的每个bucket只能存1个键值对,而Go的bucket可能存8个键值对, 所以Go可以容忍更高的负载因子。
扩容
条件
- 负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
- overflow数量 > 2^15时,也即overflow数量超过32768时。
增量式扩容
对应条件1,当负载因子过大时,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访问map时都会触发一次搬迁,每次搬迁2个键值对。
下图展示了包含一个bucket满载的map(为了描述方便,图中bucket省略了value区域):
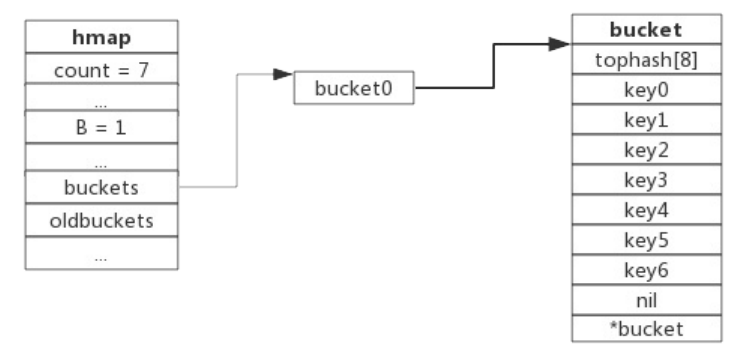
当前map存储了7个键值对,只有1个bucket。此地负载因子为7。再次插入数据时将会触发扩容操作,扩容之后再将新插入键写入新的bucket。扩容后示意图如下:
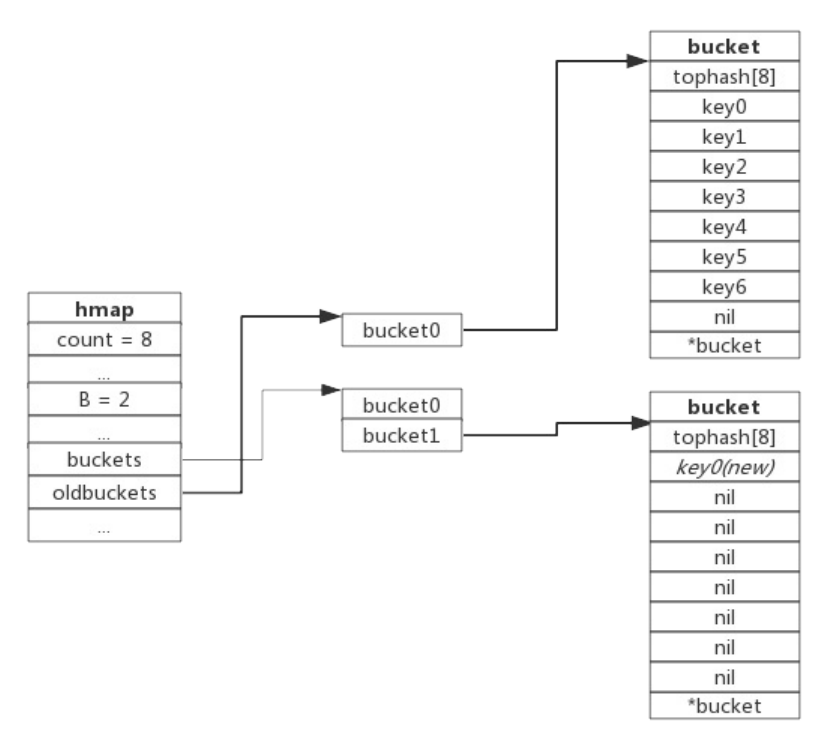
hmap数据结构中oldbuckets成员指身原bucket,而buckets指向了新申请的bucket。新的键值对被插入新的 bucket中。后续对map的访问操作会触发迁移,将oldbuckets中的键值对逐步的搬迁过来。当oldbuckets中的键 值对全部搬迁完毕后,删除oldbuckets。
搬迁完成后的示意图如下:
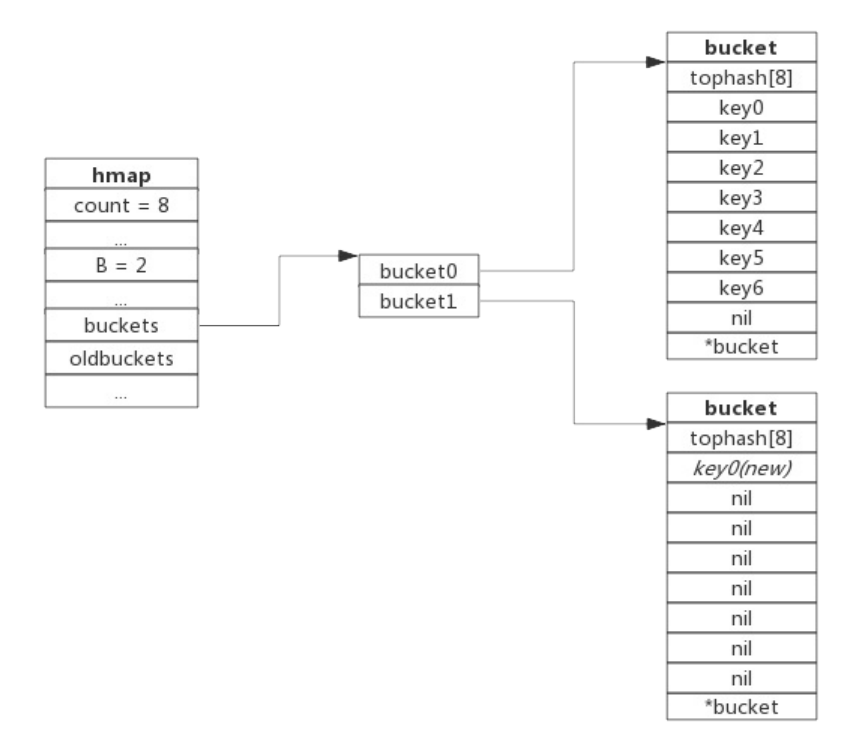
数据搬迁过程中原bucket中的键值对将存在于新bucket的前面,新插入的键值对将存在于新bucket的后面。
等量扩容
对应条件2,所谓等量扩容,实际上并不是扩大容量,buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。在极端场景下,比如不断的增删,而键值对正好集中在一小部分的bucket,这样会造成overflow的bucket数量增多,但负载因子又不高,从而无法执行增量搬迁的情况。
查找过程
跟据key值算出哈希值
取哈希值低8位与2^hmpa.B取模确定bucket位置
取哈希值高8位在tophash数组中查询
如果tophash[i]中存储值也哈希值相等,则去找到该bucket中的key值进行比较
当前bucket没有找到,则继续从下个overflow的bucket中查找。
如果当前处于搬迁过程,则优先从oldbuckets查找
注:如果查找不到,也不会返回空值,而是返回相应类型的0值。
插入过程
跟据key值算出哈希值
取哈希值低8位与2^hmap.B取模确定bucket位置
查找该key是否已经存在,如果存在则直接更新值
如果没找到将key,将key插入
删除过程
runtime/map.go
1 | // 执行delete(map, key) |
由上可知,map的删除只是将tophash置为emptyOne,它修改了当前 key 的标记,但没有直接删除了内存里面的数据。
iota
iota常用于const表达式中,iota代表了const声明块的行索引(下标从0开始) 。
示例
- 题目一
1 | const ( |
mutexLocked == 1;mutexWoken == 2;mutexStarving == 4;mutexWaiterShift == 3; starvationThresholdNs == 1000000。
- 题目二
1 | const ( |
bit0 == 1, mask0 == 0, bit1 == 2, mask1 == 1, bit3 == 8, mask3 == 7
- 题目三
1 | const ( |
a == 0,b == 1,c == str,d == 4,e == 0,f == 1
注:原理有解释。
原理
const块中每一行在GO中使用spec数据结构描述,spec声明如下:
1 | // A ValueSpec node represents a constant or variable declaration |
ValueSpec.Names这个切片中保存了一行中定义的常量,如果一行定义N个常量,那么ValueSpec.Names切片长度即为N。
const块实际上是spec类型的切片,用于表示const中的多行。
所以编译期间构造常量时的伪算法如下:
1 | for iota, spec := range ValueSpecs { |
从上面可以更清晰的看出iota实际上是遍历const块的索引,每行中即便多次使用iota,其值也不会递增。 多个const块的iota不互相影响。
string
- string是8比特字节的集合,通常但并不一定是UTF-8编码的文本。
- string可以为空(长度为0),但不会是nil。
- string对象不可以修改。
src/runtime/string.go:stringStruct 定义了string的数据结构:
1 | type stringStruct struct { |
string数据结构跟切片有些类似,只不过切片还有一个表示容量cap的成员,事实上string和切片,准确的说是byte切片经常发生转换。
字符串构建过程是先跟据字符串构建stringStruct,再转换成string。转换的源码如下:
1 | func gostringnocopy(str *byte) string { // 跟据字符串地址构建string |
string在runtime包中就是stringStruct,对外呈现叫做string。
[]byte转string
byte切片可以很方便的转换成string,如下所示:
1 | func GetStringBySlice(s []byte) string { |
需要注意的是这种转换需要一次内存拷贝。
转换过程
- 跟据切片的长度申请内存空间,假设内存地址为p,切片长度为len(b)。
- 构建string(string.str = p;string.len = len;)。
- 拷贝数据(切片中数据拷贝到新申请的内存空间) 。
注:string转[]byte同理。
转换示意图:
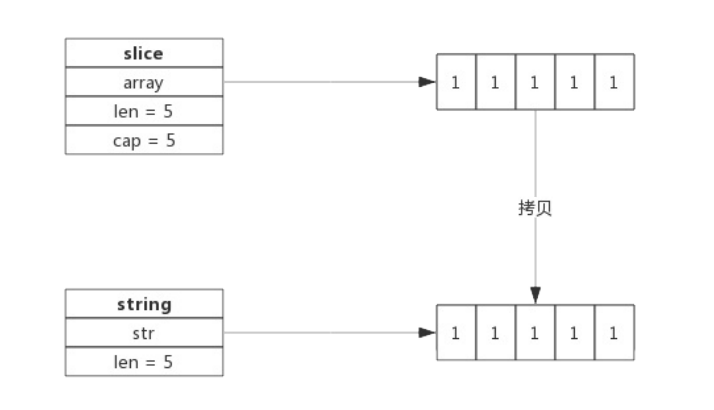
[]byte转换成string一定会拷贝内存吗?
byte切片转换成string的场景很多,为了性能上的考虑,有时候只是临时需要字符串的场景下,byte切片转换成 string时并不会拷贝内存,而是直接返回一个string,这个string的指针(string.str)指向切片的内存。 比如,编译器。
会识别如下临时场景:
- 使用m[string(b)]来查找map(map是string为key,临时把切片b转成string)。
- 字符串拼接,如”<” + “string(b)” + “>”。
- 字符串比较:string(b) == “foo” 。
因为是临时把byte切片转换成string,也就避免了因byte切片同容改成而导致string引用失败的情况,所以此时可以不必拷贝内存新建一个string。
Mutex互斥锁
1 | type Mutex struct { |
state是32位的整型变量,内部实现时把该变量分成四份,用于记录Mutex的四种状态。如下所示:
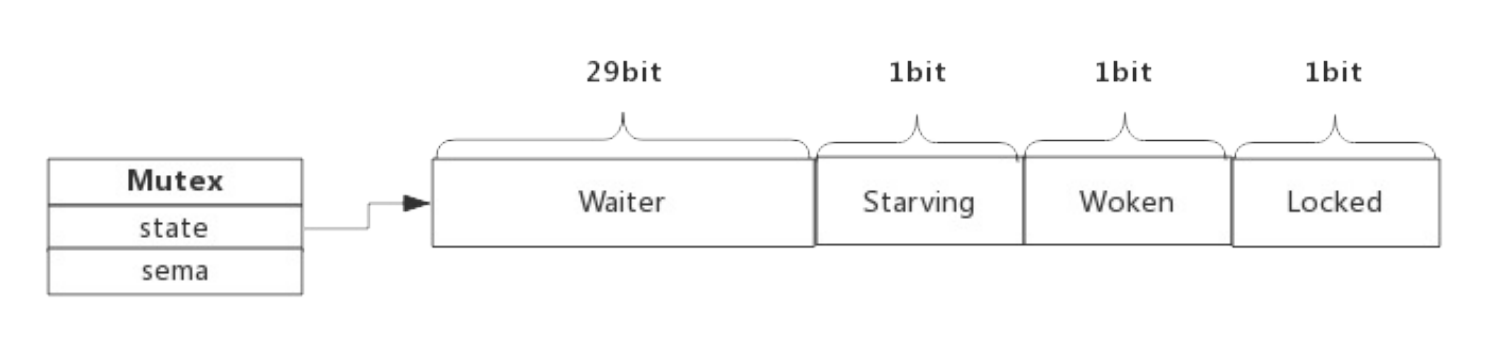
- Locked: 表示该Mutex是否已被锁定,0:没有锁定 1:已被锁定。
- Woken: 表示是否有协程已被唤醒,0:没有协程唤醒 1:已有协程唤醒,正在加锁过程中。
- Starving:表示该Mutex是否处理饥饿状态, 0:没有饥饿 1:饥饿状态,说明有协程阻塞了超过1ms。
- Waiter: 表示阻塞等待锁的协程个数,协程解锁时根据此值来判断是否需要释放信号量。
自旋
加锁时,如果当前Locked位为1,说明该锁当前由其他协程持有,尝试加锁的协程并不是马上转入阻塞,而是会持续的探测Locked位是否变为0,这个过程即为自旋过程。 自旋对应于CPU的”PAUSE”指令,CPU对该指令什么都不做,相当于CPU空转,对程序而言相当于sleep了一小段时间,时间非常短,当前实现是30个时钟周期。
自旋条件
- 自旋次数要足够小,通常为4,即自旋最多4次
- CPU核数要大于1,否则自旋没有意义,因为此时不可能有其他协程释放锁
- 协程调度机制中的Process数量要大于1,比如使用GOMAXPROCS()将处理器设置为1就不能启用自旋
- 协程调度机制中的可运行队列必须为空,否则会延迟协程调度
Mutex模式
为了避免协程长时间无法获取锁,自1.8版本以来增加了一个状态,即Mutex的Starving状态。这个状态下不会自旋,一旦有协程释放锁,那么一定会唤醒一个协程并成功加锁。
- normal模式 (默认)
加锁不成功不会立即转入阻塞排队,而是判断是否满足自旋的条件,如果满足则会启动自旋过程。
- starvation模式
自旋过程中能抢到锁,一定意味着同一时刻有协程释放了锁,我们知道释放锁时如果发现有阻塞等待的协程,还会释 放一个信号量来唤醒一个等待协程,被唤醒的协程得到CPU后开始运行,此时发现锁已被抢占了,自己只好再次阻塞, 不过阻塞前会判断自上次阻塞到本次阻塞经过了多长时间,如果超过1ms的话,会将Mutex标记为”饥饿”模式,然后再阻塞。 处于饥饿模式下,不会启动自旋过程,也即一旦有协程释放了锁,那么一定会唤醒协程,被唤醒的协程将会成功获取锁,同时也会把等待计数减1。
RWMutex读写锁
1 | type RWMutex struct { |
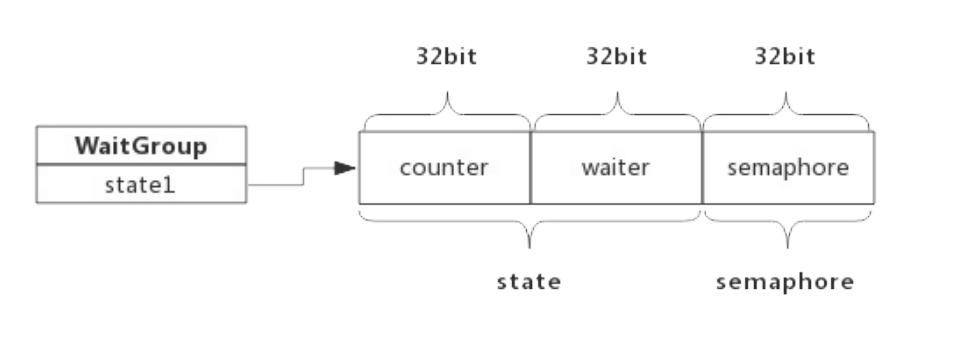
WaitGroup
源码包中 src/sync/waitgroup.go:WaitGroup 定义了其数据结构:
1 | type WaitGroup struct { |
state1是个长度为3的数组,其中包含了state和一个信号量,而state实际上是两个计数器:
- counter: 当前还未执行结束的goroutine计数器
- waiter count: 等待goroutine-group结束的goroutine数量,即有多少个等候者
- semaphore: 信号量
考虑到字节是否对齐,三者出现的位置不同,为简单起见,依照字节已对齐情况下,三者在内存中的位置如下所示:
END



